.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Der schlimmste Moment für ein wachsendes Unternehmen ist selten ein grosses Strategieproblem. Meist ist es etwas Banaleres. Der Build-Server ist morgens nicht erreichbar. Das VPN bricht kurz vor einem Kundentermin weg. Ein Zertifikat läuft unbemerkt ab. Plötzlich steht nicht nur ein System still, sondern ein Teil des Geschäfts.
Genau an dieser Stelle werden die aufgaben eines systemadministrators sichtbar. Nicht als technische Nebenrolle, sondern als operative Absicherung des Unternehmens. Für Gründer und CTOs ist das entscheidend, weil Ausfälle, Sicherheitslücken und schlecht gepflegte Infrastruktur nicht nur Nerven kosten. Sie stoppen Vertrieb, Support, Entwicklung und interne Abläufe gleichzeitig.
Wenn ein kritischer Dienst nachts ausfällt, interessiert niemanden die saubere Organigramm-Zuordnung. Dann zählt nur, ob jemand weiss, wo die Ursache liegt, wie man den Schaden eingrenzt und wie der Betrieb schnell wieder stabil läuft. Genau das ist der Kern der Rolle.
Die Arbeit eines Systemadministrators wird oft unterschätzt, weil vieles im besten Fall unsichtbar bleibt. Kein Drama, keine Ausfälle, keine Beschwerden. Aber diese Ruhe ist kein Zufall. Sie entsteht durch saubere Konfigurationen, nachvollziehbare Änderungen, regelmässige Pflege und einen klaren Wiederherstellungsplan.
Dass das kein Randthema ist, zeigt eine Zahl sehr deutlich. 82% der deutschen Unternehmen hatten mindestens einen signifikanten IT-Störungsausfall, der durchschnittliche Schaden pro Vorfall lag bei 1,2 Millionen Euro laut den genannten Bitkom-Daten zur wirtschaftlichen Wirkung von IT-Ausfällen. Für ein Tech-Unternehmen heisst das: Systemadministration ist kein Kostenblock, den man möglichst spät besetzt. Sie ist eine Form von Risikomanagement.
"Wer Infrastruktur nur dann beachtet, wenn sie ausfällt, bezahlt fast immer den höchsten Preis."
Ein guter Sysadmin sorgt dafür, dass Systeme nicht nur laufen, sondern unter Last, bei Änderungen und im Störfall berechenbar bleiben. Dazu gehört mehr als Serverpflege. Es geht um Zugriffsrechte, Monitoring, Updates, Backup-Konzepte, Netzwerkgrenzen, Dokumentation und oft auch um die Übersetzung technischer Risiken in Management-Entscheidungen.
Für Gründer ist das besonders relevant. In frühen Phasen baut man schnell, iteriert viel und verschiebt operative Hygiene gern auf später. Das funktioniert, bis das erste grössere Incident-Ticket kommt. Dann zeigt sich, ob das Unternehmen eine IT-Landschaft hat oder nur gewachsene Provisorien.
Die Rolle wird klarer, wenn man sie nicht als Einzelliste von Tätigkeiten betrachtet, sondern als vier zusammenhängende Verantwortungsbereiche. Jeder dieser Bereiche beeinflusst Stabilität, Sicherheit und Skalierbarkeit direkt.
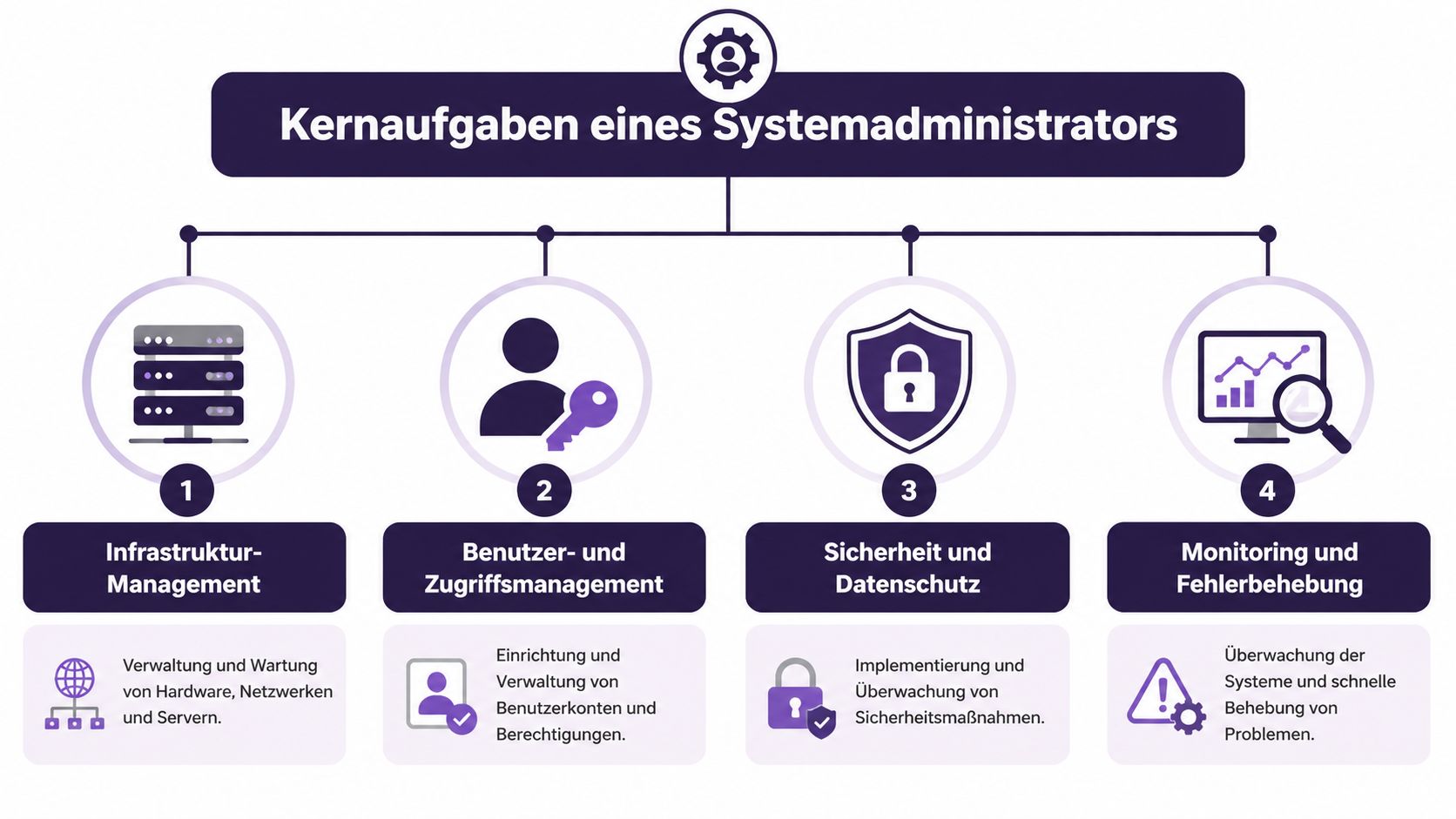
Hier geht es um Server, virtuelle Maschinen, Netzwerke, Storage, Verzeichnisdienste und oft auch Cloud-Ressourcen. Der Sysadmin installiert Systeme, aktualisiert sie kontrolliert und hält ihre Abhängigkeiten sauber. Dazu gehört auch Kapazitätsplanung. Ein System, das heute läuft, kann morgen unter neuer Last scheitern.
Ein gutes Beispiel ist Virtualisierung. Sie gehört in vielen Umgebungen zu den wichtigsten aufgaben eines systemadministrators, weil sie Ressourcen flexibler nutzbar macht. In Deutschland stellen KMU 99,6 % aller Unternehmen, und in solchen Strukturen kann Virtualisierung physische Server um bis zu 70 bis 80 % reduzieren und gleichzeitig die Ausfallsicherheit über HA-Clustering erhöhen, wie die Beschreibung zu Virtualisierung in Serverumgebungen ausführt.
Praktisch bedeutet das: weniger verstreute Hardware, bessere Auslastung, klarere Standardisierung und einfachere Wiederherstellung.
Viele Probleme entstehen nicht durch spektakuläre Angriffe, sondern durch unklare Berechtigungen. Ein ehemaliger Mitarbeiter hat noch Zugriff. Ein Dienstkonto besitzt zu viele Rechte. Ein neues Team bekommt spontan Admin-Rechte, weil es schneller geht.
Saubere Benutzerverwaltung bedeutet unter anderem:
Monitoring ist nicht einfach ein Dashboard an der Wand. Es ist die Grundlage dafür, Fehler früh zu erkennen. Gute Sysadmins beobachten CPU, Arbeitsspeicher, Festplatten, Netzwerkpfade, Zertifikate, Backup-Jobs und Service-Verfügbarkeit. Noch wichtiger ist die Alarmqualität. Zu viele irrelevante Alerts stumpfen Teams ab.
"Praxisregel: Ein Alarm ist nur dann nützlich, wenn daraus eine klare Handlung folgt."
Monitoring spart vor allem dort Geld, wo es Reaktionszeit verkürzt. Wenn das Team bereits weiss, welcher Dienst langsam wird, welche Abhängigkeit betroffen ist und seit wann sich Werte verschlechtern, wird aus hektischer Fehlersuche strukturierte Störungsbehebung.
Ein Backup ist erst dann wertvoll, wenn die Wiederherstellung getestet wurde. Dieser Punkt wird in vielen Firmen zu optimistisch behandelt. Es reicht nicht, dass irgendein Job nachts grün meldet. Ein Sysadmin prüft, ob Daten vollständig, lesbar und im Notfall rechtzeitig zurückspielbar sind.
Dazu gehören meist mehrere Ebenen:
Wer diese vier Säulen im Griff hat, betreibt IT nicht nur technisch sauber. Er schützt den Betrieb gegen die typischen Schwachstellen, die in Wachstumsphasen sonst fast zwangsläufig sichtbar werden.
Ein Arbeitstag in der Systemadministration ist selten linear. Es gibt geplante Aufgaben, wiederkehrende Prüfungen und jederzeit die Möglichkeit, dass ein Incident alles verschiebt. Genau diese Mischung macht die Rolle anspruchsvoll.

Ein erfahrener Sysadmin startet nicht blind in Tickets. Er prüft zuerst, was in der Nacht passiert ist. Dazu gehören Backup-Berichte, fehlgeschlagene Jobs, ungewöhnliche Lastspitzen, Warnungen aus dem Monitoring und Änderungen aus dem letzten Deployment-Fenster.
Wenn dort bereits Fehler auftauchen, wird priorisiert. Nicht jede Warnung ist kritisch. Aber jede Warnung braucht Kontext. Ist ein einzelner Dienst kurzzeitig neu gestartet, oder kündigt sich ein grösseres Problem an, etwa voller Storage oder ein schleichender Performance-Einbruch in einer Datenbank-nahen Anwendung?
Danach folgen oft geplante Arbeiten. Zum Beispiel ein Update auf einem Testsystem, ein Zertifikatsaustausch, das Nachziehen einer Gruppenrichtlinie oder die Vorbereitung eines neuen Benutzer-Setups für ein Teammitglied.
Gegen späten Vormittag kippt der Tag häufig. Ein internes Tool ist nicht erreichbar, eine API antwortet langsam oder ein externer Dienst verursacht Timeouts in einer Anwendung. Jetzt trennt sich Routine von echter Betriebssicherheit.
Gute Sysadmins arbeiten in solchen Momenten nach Reihenfolge:
"In vielen Teams scheitert Troubleshooting nicht an fehlendem Wissen, sondern an ungeordneter Reaktion."
Später am Tag verschiebt sich die Arbeit oft wieder in den strategischen Bereich. Ein Skript für Benutzer-Onboarding wird verbessert. Ein Patch-Fenster wird vorbereitet. Alte Freigaben werden bereinigt. Dokumentation wird nachgezogen, weil eine Änderung sonst in wenigen Wochen wieder Rätsel aufgibt.
Ein realistischer Eindruck von der Rolle zeigt auch dieses Video:
In schwachen Setups verbringt der Sysadmin den ganzen Tag im Feuerlöschmodus. In stabilen Setups gibt es klare Wartungsfenster, definierte Eskalationswege, automatisierte Standardaufgaben und saubere Runbooks. Der Unterschied ist nicht akademisch. Er entscheidet darüber, ob Administration eine Dauerkrise bleibt oder ein belastbarer Betriebsprozess wird.
Ein moderner Sysadmin braucht kein beliebiges Sammelsurium an Tools, sondern ein stimmiges Set für Betrieb, Transparenz und Änderungen. Entscheidend ist weniger, ob ein Team Tool A oder Tool B nutzt. Entscheidend ist, ob die Werkzeuge sauber ineinandergreifen.

Die Basis bilden meist Linux und Windows Server. Linux ist in vielen Web-, Container- und Automatisierungsumgebungen der Standard. Windows Server bleibt relevant, sobald Active Directory, klassische Unternehmenssoftware oder hybride Office-Umgebungen im Spiel sind.
Dazu kommen Cloud-Plattformen wie AWS und Azure. Ein Sysadmin verwaltet dort keine abstrakte “Cloud”, sondern konkrete Ressourcen. Virtuelle Maschinen, Identity-Dienste, Netzsegmente, Storage, Protokollierung und Richtlinien.
Ohne Sichtbarkeit arbeitet Administration im Blindflug. Gängige Werkzeuge in diesem Bereich sind:
Diese Werkzeuge liefern aber nur dann Nutzen, wenn Schwellwerte und Verantwortlichkeiten klar sind. Ein Dashboard ohne Alarmdisziplin wird schnell zur Deko.
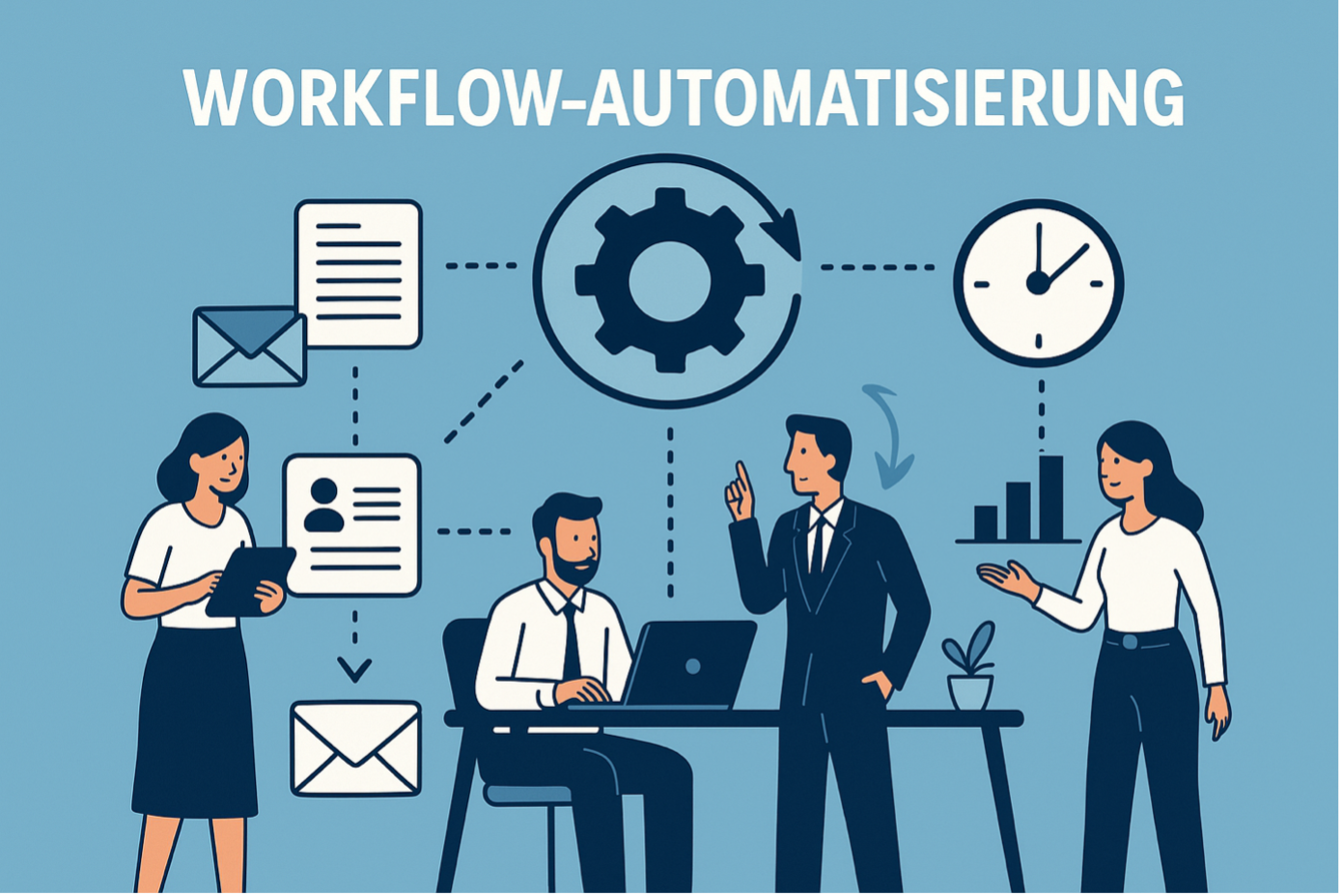
Wiederkehrende Aufgaben sollten nicht manuell bleiben. Benutzer anlegen, Pakete aktualisieren, Konfigurationen ausrollen oder Dienste prüfen. Solche Abläufe lassen sich mit Ansible, PowerShell oder Bash standardisieren.
Das senkt nicht nur den Aufwand. Es reduziert auch die Varianz. Wenn jeder Admin denselben Standardprozess ausführt, sinkt das Risiko für abweichende Konfigurationen erheblich.
Wer als Tech Lead die Brücke zwischen Betrieb und Entwicklung besser verstehen will, findet im Beitrag zu Continuous Integration im Entwicklungsalltag einen guten Anschluss an die Frage, wie Änderungen kontrollierter in produktive Umgebungen gelangen.
"Gute Automatisierung ersetzt nicht das Denken. Sie ersetzt wiederholbare Handgriffe, damit Zeit für Analyse bleibt."
Ein unterschätzter Punkt ist der physische Arbeitsplatz. Sysadmins verbringen viel Zeit mit Terminals, Dashboards, Logfiles und Fernwartung. Wer täglich zwischen mehreren Fenstern, Konsolen und Tickets wechselt, merkt schnell, dass Eingabegeräte einen Unterschied machen. Gerade für längere Wartungsfenster oder Incident-Arbeit können Vorteile ergonomischer Eingabegeräte den Arbeitsalltag spürbar verbessern.
Nicht jedes Tool muss perfekt sein. Aber die Kombination aus Plattformwissen, Monitoring, Automatisierung und einem funktionalen Arbeitsplatz ist das, was einen Sysadmin im Alltag wirklich produktiv macht.
Sicherheit ist kein Zusatzpaket, das man später auf die Infrastruktur legt. Sie steckt in Konten, Firewall-Regeln, Patch-Ständen, Logging, Zugriffspfaden und in der Frage, wie konsistent Änderungen umgesetzt werden. Genau deshalb gehören Sicherheit und Automatisierung fachlich zusammen.
Der Druck ist real. Der BSI-Report 2024 meldete 82.000 Angriffe auf KMU. Zu den Kernaufgaben gehört deshalb, Firewalls zu konfigurieren, Intrusion Detection Systems einzusetzen, Zero-Trust-Modelle zu nutzen und mit regelmässigen Vulnerability-Scans die Reaktionszeit auf Vorfälle deutlich zu verkürzen, wie die Beschreibung zu Netzwerksicherheit in der Systemadministration zusammenfasst.
Die meisten Teams kennen die richtigen Massnahmen. Das Problem ist meistens nicht Unwissen, sondern ungleichmässige Umsetzung. Der eine Server ist gepatcht, der andere wartet noch. Ein Benutzer wird sauber onboarded, beim Offboarding bleibt aber ein Alt-Zugang offen. Eine Firewall-Regel wird temporär geöffnet und nie wieder entfernt.
Hier zeigt sich der strategische Wert der aufgaben eines systemadministrators. Gute Administration übersetzt Sicherheitsanforderungen in wiederholbare Betriebsprozesse. Nicht als einmaliges Projekt, sondern als laufende Disziplin.
Praktisch heisst das oft:
Automatisierung wird häufig nur mit Effizienz begründet. Das greift zu kurz. In der Praxis ist sie ein Sicherheitswerkzeug. Ein automatisiertes Patch-Skript arbeitet konsistenter als ein ad hoc durchgeführtes Update unter Zeitdruck. Eine standardisierte Benutzeranlage verhindert vergessene Gruppen oder überhöhte Rechte. Eine wiederholbare Server-Basis reduziert Konfigurationsabweichungen.
Besonders in wachsenden Unternehmen ist das entscheidend. Je mehr Systeme, Teams und Standorte dazukommen, desto weniger funktioniert Sicherheitsarbeit auf Zuruf. Dann braucht es technische Leitplanken.
Ein naheliegendes Beispiel ist Single Sign-on in Kombination mit sauberem Passwort- und Rechtekonzept. Wer die organisatorische Seite dieses Themas vertiefen will, findet im Beitrag zu SSO und Passwort-Management für die IT-Sicherheit von Mitarbeitern eine gute Ergänzung.
"Sicherheit wird erst belastbar, wenn Standardfälle ohne Improvisation sauber ablaufen."
Gerade für Führungskräfte ist wichtig: Datenschutz ist nicht nur ein juristischer Textbaustein. Er hängt operativ an Zugriffsrechten, Speicherorten, Protokollierung und Löschprozessen. Wer dazu einen gut lesbaren Einstieg sucht, findet bei Informationen zum Datenschutz eine hilfreiche Übersicht über die organisatorische Perspektive.
Ein erfahrener Sysadmin denkt deshalb bei jeder Änderung mit. Wer bekommt Zugriff. Wo landen Logs. Welche Daten wandern in Drittsysteme. Wie wird im Vorfall dokumentiert. Diese Fragen sind nicht bürokratisch. Sie entscheiden darüber, ob ein Unternehmen handlungsfähig und prüfbar bleibt.
Die Arbeit eines Systemadministrators lässt sich schlecht über Bauchgefühl bewerten. “Läuft meistens” ist kein Führungsinstrument. Wer die Rolle professionell steuern will, braucht KPIs und SLAs, die den tatsächlichen Betriebszustand abbilden.
Ein KPI misst Leistung oder Stabilität. Ein SLA definiert, welches Service-Niveau intern oder gegenüber Fachbereichen zugesichert wird. Beides sollte zusammenpassen. Wenn ein SLA kurze Reaktionszeiten verspricht, muss das Team auch die nötigen Messpunkte haben, um diese Zeiten zu verfolgen.
Nicht jede Metrik ist nützlich. Sinnvoll sind Kennzahlen, die Entscheidungen erleichtern und Probleme früh sichtbar machen.
Drei Regeln haben sich bewährt:
Wer diese Kennzahlen mit Produkt- und Unternehmenszielen verknüpfen will, findet im Beitrag zu KPI und Business Intelligence in der Praxis eine sinnvolle Anschlussfrage. Vor allem für CTOs ist das wichtig, weil Betriebsqualität sonst oft neben Delivery-Kennzahlen untergeht.
Einen guten Sysadmin einzustellen ist aktuell kein Nebenprojekt des HR-Teams. Es ist eine Management-Entscheidung. Der Markt ist eng, und die Rolle wird in vielen Unternehmen erst ernst genommen, wenn bereits operative Schmerzen da sind.
Die Herausforderung ist klar umrissen. 2025 gibt es in Deutschland laut StepStone über 45.000 offene Stellen für Systemadministratoren, bei einem allgemeinen IT-Fachkräftemangel von 137.000. Das Durchschnittsgehalt liegt bei 62.500 Euro laut den Arbeitsmarktangaben zu Systemadministratoren in Deutschland. Für Arbeitgeber heisst das: Wer unscharf sucht, sucht lange.
Zertifikate können hilfreich sein, aber sie ersetzen keine Betriebserfahrung. Besser sind Fragen, die Arbeitsweise sichtbar machen:
Gute Kandidaten antworten nicht nur mit Tool-Namen. Sie beschreiben Priorisierung, Kommunikation, Absicherung und Nachbereitung.
"Der Unterschied zwischen Theorie und Praxis zeigt sich oft daran, ob jemand über Systeme oder über Konsequenzen spricht."
Selbst starke Admins scheitern, wenn sie als isolierte Feuerwehr eingesetzt werden. Damit die Zusammenarbeit funktioniert, braucht es vom ersten Tag an Zugriff auf Dokumentation, Architekturüberblick, klare Zuständigkeiten und feste Kommunikationswege mit Entwicklung, Support und Management.
Besonders wichtig ist die Erwartungshaltung. Ein Sysadmin ist nicht nur für “alles Technische” zuständig. Die Rolle braucht Prioritäten, Wartungsfenster und Rückhalt für unpopuläre, aber notwendige Entscheidungen wie Patching, Härtung oder Rechteentzug. Erst dann wird aus einer guten Einzelperson ein verlässlicher Betriebsfaktor.
Der Unterschied liegt vor allem im Verantwortungsfokus. Ein Systemadministrator hält produktive Systeme verlässlich am Laufen. Dazu gehören Server, Benutzerkonten, Netzwerke, Backups, Monitoring, Patching und Zugriffsrechte. Das Ziel ist ein stabiler, sicherer Betrieb mit möglichst wenig Ausfallzeit.
Ein DevOps-Engineer arbeitet näher an der Delivery-Kette zwischen Entwicklung und Betrieb. Typische Themen sind CI/CD-Pipelines, Infrastruktur als Code, Container-Plattformen, Standardisierung und automatisierte Deployments. In kleineren Teams übernimmt eine Person oft beide Bereiche. Sobald Systeme, Teams und Risiken wachsen, spart eine klare Trennung Zeit, senkt Fehlerquoten und verbessert die Reaktionsfähigkeit im Incident.
Am Anfang nicht zwingend in Vollzeit.
Ein junges Startup mit wenigen internen Systemen, klarer Cloud-Architektur und überschaubarem Supportaufwand kann Systemadministration extern oder anteilig abdecken. Das funktioniert aber nur, wenn Verantwortlichkeiten sauber geregelt sind. Wer ist bei einem Ausfall erreichbar? Wer prüft Backups? Wer gibt Rechte frei? Wer entscheidet über Patches in produktiven Systemen?
Sobald mehrere geschäftskritische Dienste laufen, Kundendaten verarbeitet werden oder Ausfälle direkten Umsatzverlust bedeuten, reicht lose Zuständigkeit nicht mehr. Dann braucht es eine feste operative Rolle. Nicht aus formalen Gründen, sondern weil Betriebsrisiken sonst zwischen Entwicklung, Support und Management hängen bleiben.
Systemadministration ist kein einheitliches Berufsbild. In der Praxis entstehen Spezialisierungen dort, wo Komplexität und Risiko steigen. Häufig sind das Netzwerkadministration, Cloud-Administration, Datenbankbetrieb, Identity- und Access-Management, Microsoft- oder Linux-Betrieb sowie Security-naher Infrastrukturbetrieb.
Für wachsende Unternehmen ist diese Einordnung wichtig. Ein Admin mit starker Windows- und M365-Erfahrung löst andere Probleme als jemand, der Kubernetes-Cluster, Terraform und AWS-Accounts betreut. Wer Ausbildungswege und typische Entwicklungsrichtungen genauer einordnen möchte, findet unter Informationen zur IT-Ausbildung einen ergänzenden Überblick.
Wenn Sie ein Produktteam aufbauen oder Ihre Delivery-Kapazität erweitern möchten, unterstützt PandaNerds Unternehmen dabei, erfahrene Entwickler ohne Reibungsverluste in bestehende Teams zu integrieren. Gerade dort, wo Entwicklung, Plattform und Betrieb sauber zusammenspielen müssen, verbessert erfahrene Verstärkung Tempo, Qualität und Verlässlichkeit.
































































































.svg)


