.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Ein Produktteam startet oft mit einer einzelnen Datenbank, ein paar Dashboards und einem ETL-Job pro Nacht. Ein Jahr später kommen Event-Streams aus der App dazu, Logdaten aus mehreren Services, Support-Texte aus dem CRM und vielleicht noch Sensordaten oder Bilder. Die Zahlen wachsen nicht nur. Sie bewegen sich schneller, kommen in mehr Formaten an und belasten plötzlich genau die Systeme, die gestern noch ausgereicht haben.
TL;DR: Der Begriff beschreibt eine Datenpraxis, in der Volume, Velocity und Variety so stark zunehmen, dass klassische Datenbanken, Reporting-Setups und Einzelsysteme an ihre Grenzen kommen. Dann braucht ihr verteilte Speicherung, andere Verarbeitungsmuster und eine klarere Datenorganisation im Team.
Viele Entwicklergruppen erkennen diesen Punkt erst, wenn die Symptome schon im Produkt spürbar sind. Abfragen dauern zu lange. Dashboards widersprechen sich. Operative Systeme werden durch Analysen ausgebremst. Und Entscheidungen stützen sich wieder stärker auf Annahmen als auf belastbare Kennzahlen.
Für Tech Leads ist das vor allem keine Definitionsfrage, sondern eine Architekturfrage. Daten verhalten sich dann wie Verkehr in einer Stadt, die für wenige tausend Autos geplant war und jetzt Millionen Bewegungen pro Tag koordinieren muss. Mehr Asphalt allein löst das Problem nicht. Ihr braucht andere Straßen, andere Regeln und oft auch andere Rollen im Team.
Darum geht es in diesem Leitfaden. Nicht um ein Schlagwort, sondern um die praktische Umsetzung. Also um die Frage, wann ein technischer Wechsel nötig wird, welche Architektur dafür passt und mit welchem ersten Stack ihr sinnvoll startet, ohne euer Team mit zu viel Komplexität zu überladen.
Big Data ist nicht einfach nur „sehr viele Daten“. Das wäre zu kurz gedacht.
Big Data beginnt an dem Punkt, an dem eure bisherigen Werkzeuge scheitern. Wenn ein relationales Datenbanksystem, ein klassisches BI-Setup oder ein einzelner Analyse-Server die Last nicht mehr zuverlässig trägt, braucht ihr andere Architekturen, andere Speicherformen und andere Verarbeitungsmodelle.

In einem wachsenden Produktteam zeigt sich das oft an sehr konkreten Symptomen:
Big Data ist die Antwort auf genau diese Lage. Es ist also weniger ein Datentyp als ein technologischer Wechsel.
Der Begriff Big Data wurde Mitte der 1990er Jahre von John Mashey bei Silicon Graphics geprägt. Er warnte damals bereits, dass Computer durch exponentiell wachsendes Datenvolumen an Grenzen stoßen würden. Diese Einschätzung war treffend, weil sich die globale Datenmenge seitdem etwa alle zwei Jahre verdoppelt (Tink zur Historie von Big Data).
"Big Data ist kein Modewort. Es ist ein Hinweis darauf, dass euer altes Verarbeitungsmodell nicht mehr zur Realität eures Produkts passt."
Für Entwickler ist das der entscheidende Punkt. Sobald Daten nicht mehr sinnvoll auf einem zentralen System verarbeitet werden können, denkt ihr in Clustern, verteiltem Storage, Pipelines und Fehlertoleranz. Dann verschiebt sich die Aufgabe von „Daten speichern“ zu „Daten zuverlässig nutzbar machen“.
Die bekannte Kurzform sind die 3 Vs. Für saubere Architektur reichen sie meist nicht aus. In der Praxis helfen fünf Dimensionen mehr: Volume, Velocity, Variety, Veracity, Value.
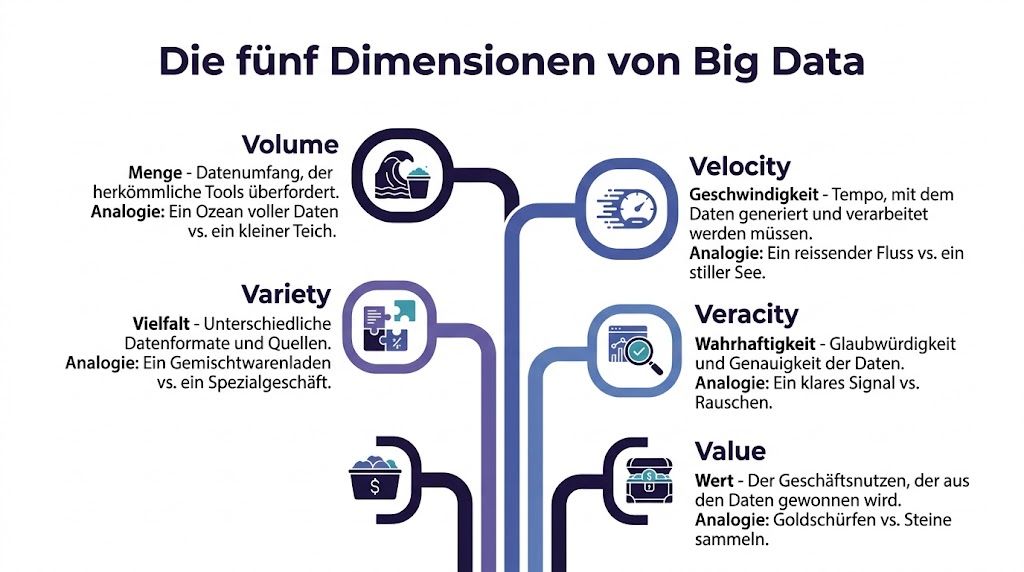
Volume meint die Menge. Ein einzelner CSV-Export ist kein Problem. Millionen Events, historische Logs, Bilddaten und Produktinteraktionen über längere Zeiträume verändern dagegen alles. Storage, Partitionierung und Query-Strategie werden plötzlich Kernfragen.
Velocity meint das Tempo. Ein Monatsreport kann warten. Fraud Detection, Monitoring oder dynamische Empfehlungen können das nicht. Wenn Daten kontinuierlich einlaufen, reicht Batch-Denken oft nicht mehr.
Variety meint die Vielfalt. Klassische Business-Systeme arbeiten gern mit klaren Tabellen. Moderne Produkte erzeugen aber strukturierte und unstrukturierte Daten nebeneinander. API-Payloads, Texte, Videos, Clickstreams und Sensordaten folgen nicht derselben Logik.
Eine einfache Analogie hilft:
Viele Teams stoppen bei den ersten drei Vs. Das ist meist der Fehler.
Veracity steht für Datenqualität. Wenn Felder fehlen, Events falsch benannt sind oder Zeitstempel inkonsistent ankommen, wird jede Analyse fragwürdig. Laut Datasolut zu Veracity und unstrukturierten Daten liegen circa 90 % aller gespeicherten Daten in unstrukturierten Formaten wie Texten, Bildern oder Videos vor. Genau deshalb sind Datenbereinigung und Validierung keine Nebenaufgabe.
Value fragt nach dem Nutzen. Ein voller Data Lake ist noch kein Geschäftswert. Wert entsteht erst, wenn Teams bessere Entscheidungen treffen, Prozesse automatisieren oder Risiken früher erkennen.
"Praxisregel: Wenn ihr kein konkretes Produktproblem, keine operative Entscheidung oder keinen klaren Analysefall benennen könnt, braucht ihr noch kein Big-Data-Programm. Ihr braucht zuerst einen Anwendungsfall."
Für „big data einfach erklärt“ ist das die wichtigste Vereinfachung: Nicht jede große Datenmenge ist automatisch wertvoll. Erst gute Daten plus sinnvolle Verarbeitung machen daraus ein belastbares System.
Architektur wird bei Big Data schnell abstrakt. Sie lässt sich einfacher verstehen, wenn man erst auf die Grundstruktur schaut.
Laut SAP zur Big-Data-Architektur und MapReduce besteht Big Data aus einer vierschichtigen Architekturstruktur mit Datenquellen, Datenspeicherung, Analyse und Business-Intelligence-Schicht. Das Herzstück ist die parallele Verarbeitung auf massiven Clustern durch Verfahren wie MapReduce. Dadurch wird Verarbeitung innerhalb von Millisekunden möglich.
Ein realistisches Setup sieht meist so aus:
Die technische Kunst liegt nicht darin, diese vier Ebenen zu benennen. Sie liegt darin, Übergänge sauber zu bauen. Genau dort scheitern viele Projekte.
Die nützlichste Unterscheidung für den Einstieg ist diese:
Ein Data Lake speichert Rohdaten. Ein Data Warehouse speichert aufbereitete, strukturierte Daten für Reporting und Analyse.
Denkt an eine Küche. Der Data Lake ist die Speisekammer mit Zutaten, Verpackungen und halbfertigen Dingen. Das Data Warehouse ist das angerichtete Menü, standardisiert und sofort servierbar.
Wer sich tiefer mit analytischen Verfahren beschäftigt, findet im Beitrag zur Big-Data-Analyse in der Praxis eine gute Ergänzung für den operativen Blick.
Lambda-Architektur trennt Batch- und Stream-Verarbeitung. Das ist zuverlässig, aber komplexer im Betrieb, weil zwei Verarbeitungspfade gepflegt werden.
Kappa-Architektur setzt stärker auf Stream-Verarbeitung als zentrales Modell. Das vereinfacht manches, verlangt aber Disziplin bei Event-Design, Replay und Zustandsverwaltung.
Für viele Teams gilt eine pragmatische Regel: Fangt nicht mit dem Architektur-Namen an. Fangt mit der Frage an, ob euer Produkt eher periodische Analysen, laufende Reaktionen oder beides braucht.
Wer Big Data baut, arbeitet selten mit einem einzigen Tool. Der Stack besteht aus Bausteinen mit klarer Rolle.
Die wichtigste Vereinfachung lautet: Storage hält Daten verfügbar. Processing macht sie nutzbar. Streaming bewegt sie durch das System.

HDFS steht für ein verteiltes Dateisystem im Hadoop-Umfeld. Es wurde dafür gebaut, große Datenmengen über mehrere Rechner zu speichern. Das ist nützlich, wenn ihr klassische Hadoop-nahe Workloads betreibt.
Amazon S3 oder vergleichbare Objektspeicher in anderen Clouds lösen ein ähnliches Problem anders. Sie speichern Objekte statt Dateisystem-Blöcke und sind für viele moderne Setups die einfachere Basis. Gerade für kleine und mittlere Teams ist das oft operativ angenehmer als ein selbst verwaltetes Cluster.
Apache Spark ist für viele Teams der praktische Einstieg in skalierbare Verarbeitung. Spark ist vor allem für In-Memory-Verarbeitung bekannt, was Datenverarbeitung deutlich beschleunigen kann. Wenn ihr wissen wollt, wann welches Framework besser passt, hilft der Vergleich Spark vs. Hadoop im direkten Praxisbezug.
Apache Kafka übernimmt typischerweise die Rolle des Event-Backbones. Es puffert und verteilt Datenströme zuverlässig zwischen Produzenten und Konsumenten.
Apache Flink ist stark, wenn kontinuierliche Verarbeitung mit Zuständen, Zeitfenstern und Streaming-Logik im Vordergrund steht.
Ein solider Start für viele Produktteams sieht so aus:
"Wenn euer erster Use Case kein echtes Echtzeitproblem hat, startet mit einem einfachen Batch-Stack. Ein zu früher Stream-Stack macht Betrieb, Debugging und Onboarding schwerer."
Die beste Technologie ist nicht die mächtigste. Es ist diejenige, die euer Team zuverlässig betreiben, testen und weiterentwickeln kann.
Big Data wird erst verständlich, wenn man den Weg vom Rohsignal zur Produktentscheidung sieht.
Ein Anwendungsfall ist gut, wenn das Team klar sagen kann: Diese Datenquelle löst genau dieses operative Problem.

Ein Maschinenbauer sammelt laufend Sensordaten aus Anlagen. Temperatur, Vibration und Fehlermeldungen kommen kontinuierlich herein. Einzelne Signale sagen wenig. Im Verlauf zeigen sie aber Muster vor einem Ausfall.
Der Geschäftswert entsteht nicht durch das Sammeln der Sensordaten. Er entsteht, wenn das Team Wartung gezielter plant, Ausfälle früher erkennt und Service-Einsätze besser priorisiert.
Ein Shop verarbeitet Klickpfade, Suchanfragen, Warenkorb-Ereignisse und Käufe. Diese Daten kommen aus verschiedenen Quellen und in unterschiedlicher Form.
Mit einem guten Datenmodell kann das Produktteam Empfehlungen, Sortierung oder Suchergebnisse an den aktuellen Kontext anpassen. Das verbessert nicht nur Marketing, sondern auch Produktlogik, Merchandising und Bestandssteuerung. Wer KI-nahe Musterfälle weiterdenken will, findet bei künstliche Intelligenz Lösungen für Unternehmen gute Anschlussideen.
Im Finanzumfeld muss eine Plattform Transaktionen sehr schnell bewerten. Dabei reicht eine einzelne Regel selten aus. Erst die Kombination aus Historie, Gerätedaten, Verhaltensmustern und Kontext macht eine Bewertung belastbar.
Hier zeigt sich der Unterschied zwischen klassischer Analyse und Big Data besonders klar. Das System muss Daten nicht nur speichern, sondern im richtigen Moment verfügbar machen.
Zur Einordnung passt auch dieses kurze Video:
"Gute Big-Data-Produkte beantworten keine abstrakten Fragen. Sie unterstützen eine konkrete Entscheidung, bevor der Zeitpunkt vorbei ist."
Ein typisches Muster in Big-Data-Projekten sieht so aus: Das Team bekommt schnell neue Datenquellen angebunden, erste Dashboards sehen vielversprechend aus, und nach wenigen Monaten streitet man über Zahlen, Kosten und Zuständigkeiten. Das Problem liegt dann selten nur im Storage oder im Processing. Es liegt im System rund um die Daten.
Mit wachsender Datenmenge steigen auch die Anforderungen an Architektur, Betrieb und Zusammenarbeit. Wer hier nur an Technologie denkt, baut eine Plattform, die Daten sammelt, aber Entscheidungen nicht verlässlich unterstützt. Für Tech-Leads und Produktverantwortliche ist deshalb eine andere Frage wichtiger als die Auswahl einzelner Tools: Welche organisatorischen und technischen Regeln machen aus vielen Daten ein belastbares Produkt?
Viele Teams behandeln Datenspeicherung wie einen grossen Lagerraum. Erst einmal alles hinein, später sortieren. In der Praxis wird genau das teuer.
Kosten entstehen, wenn Rohdaten ohne Zweck gehalten werden, dieselben Informationen in mehreren Schichten liegen oder Transformationen dauerhaft laufen, obwohl sie kaum genutzt werden. Ein gutes Kostenmodell beginnt deshalb beim Use Case und beim Datenlebenszyklus. Wer von Anfang an festlegt, welche Daten für operative Entscheidungen, Analysen oder Audits gebraucht werden, vermeidet überflüssige Pipelines und unnötige Retention.
Hilfreich sind vier Architekturfragen:
Für den Einstieg ist oft ein kleiner, klar abgegrenzter Stack besser als eine Plattform mit zu vielen Bausteinen. Ein Team, das Kosten, Latenz und Datenhaltung versteht, skaliert kontrollierter als ein Team mit fünf neuen Tools und ohne Betriebsmodell.
Governance wird oft als Regelwerk für Compliance missverstanden. Für Entwicklerteams ist sie vor allem ein Mittel gegen Reibung.
Wenn niemand sauber definiert hat, was ein Kunde, eine Bestellung oder ein aktiver Nutzer genau ist, baut jedes Team sein eigenes Modell. Dann entstehen Abweichungen in Metriken, Diskussionen in Reviews und Unsicherheit bei Produktentscheidungen. Governance schafft hier gemeinsame Begriffe, klare Eigentümer und nachvollziehbare Zugriffe. Das beschleunigt Delivery, weil weniger Interpretationsarbeit anfällt.
Datenschutz gehört in denselben Architekturrahmen. As noted earlier, Big Data bringt Daten aus vielen Quellen zusammen. Genau deshalb müssen Zugriffsebenen, Pseudonymisierung, Aufbewahrungsfristen und Protokollierung früh mitgedacht werden. Wer das erst nach dem Go-live ergänzt, baut an einer laufenden Maschine um.
Solide Mindestregeln sind:
Mehr Daten verbessern kein schlechtes Signal. Sie vervielfachen nur den Fehler.
Gerade in skalierenden Produkten beginnt Datenqualität nicht im BI-Tool, sondern an der Quelle: bei Event-Namen, Pflichtfeldern, IDs, Zeitstempeln und semantisch klaren Definitionen. Ein fehlerhaftes Tracking verhält sich wie ein Sensor mit Wackelkontakt. Einzelne Werte sehen plausibel aus, aber auf Systemebene wird jede Auswertung unsicher.
Deshalb brauchen Datenpipelines dieselbe technische Disziplin wie produktive Software. Dazu gehören Schema-Validierung, Tests in Transformationen, Monitoring für Ausfälle und Warnungen bei Anomalien in Volumen oder Verteilung. Wer Daten als Produktbestandteil behandelt, erkennt Fehler früher und schützt das Vertrauen der Fachseite.
"Wer Datenqualität nicht misst, baut keine Datenplattform. Er baut eine teure Gerüchteküche."
Viele Big-Data-Initiativen scheitern nicht an fehlenden Tools, sondern an unklarer Verantwortung. Data Engineering, Plattformbetrieb, Analytics und Fachbereich arbeiten dann nebeneinander statt miteinander.
Für den Start reicht oft ein kleines Team mit klaren Zuständigkeiten: jemand für Datenintegration und Pipelines, jemand für Modellierung und Auswertung, jemand mit Produkt- oder Domänenverantwortung. Entscheidend ist, dass technische Entscheidungen an einen echten Anwendungsfall gebunden bleiben. Sonst optimiert das Team für Infrastruktur, aber nicht für Wirkung.
Der kritische Erfolgsfaktor lautet daher nicht "mehr Daten", sondern "klare Entscheidungen über Daten". Genau dort trennt sich ein spannendes Experiment von einer Big-Data-Plattform, die im Alltag trägt.
Der Einstieg scheitert oft nicht an Technologie, sondern an der falschen Projektlogik. Teams planen zu gross, kaufen zu früh ein und definieren den Nutzen zu spät.
Für KMUs und Scale-ups gibt es laut Salesforce zur Implementierungslücke bei Big Data genau diese Hürde: Die Theorie ist bekannt, aber die Integration der Tools in bestehende Teams bleibt unklar. Der Erfolg hängt daran, ob Senior-Entwickler-Skills für Datenqualität und Pipeline-Aufbau vorhanden sind.
Startet nicht mit Hadoop, Spark oder Kafka als Ziel. Startet mit einer operativen Frage.
Geeignet sind Fälle wie Anomalie-Erkennung, bessere Forecasts, Personalisierung, Qualitätskontrolle oder schnellere Produktanalysen. Wichtig ist, dass eine fachliche Entscheidung daran hängt.
Ein schlechter Start lautet: „Wir bauen erst mal einen Data Lake.“
Ein guter Start lautet: „Wir wollen Rohdaten aus drei Systemen so zusammenführen, dass das Team Ausfälle früher erkennt.“
Ein sinnvoller Einstieg ist ein begrenzter Proof of Concept mit echtem Datenfluss. Nicht monatelang im Labor, sondern so, dass ihr Ingestion, Storage, Transformation und Auswertung einmal vollständig durchspielt.
Praktisch heisst das oft:
Big Data ist kein Nebenprojekt für ein überlastetes Backend-Team. Ihr braucht meist Kompetenzen in mehreren Rollen:
Entscheidend ist nicht, ob alle Rollen sofort full time vorhanden sind. Entscheidend ist, dass die nötigen Fähigkeiten abgedeckt sind.
Viele Teams brauchen Spezialwissen nur phasenweise. Etwa beim Aufsetzen eines Event-Schemas, bei Spark-Jobs, bei Kafka-Topologien oder beim Design einer belastbaren Pipeline.
Dann ist es oft effizienter, gezielt erfahrene Unterstützung für Architektur und Enablement dazuzuholen, statt monatelang auf seltene Spezialisten zu warten. Wichtig ist nur, dass Wissen ins interne Team übergeht und nicht in einer Black Box verschwindet.
Die richtige Reihenfolge ist daher einfach: Problem klar machen, kleinen produktionsnahen Scope wählen, Teamlücken bewusst schliessen, dann sauber erweitern.
Nein. Auch kleinere Produktteams stoßen schnell auf typische Big-Data-Muster, etwa bei Event-Daten, Logs, Bilddaten oder IoT-Signalen. Entscheidend ist nicht die Unternehmensgröße, sondern ob klassische Werkzeuge euren Datenfluss noch zuverlässig abbilden.
Nein. Viele sinnvolle Anwendungsfälle funktionieren gut mit Batch-Verarbeitung. Echtzeit lohnt sich dort, wo eine Entscheidung sofort getroffen werden muss, etwa bei Monitoring, Betrugserkennung oder Live-Personalisierung. Für viele Teams ist ein guter täglicher oder stündlicher Pipeline-Lauf der bessere erste Schritt.
Der häufigste Fehler ist ein Technologieprojekt ohne klaren Geschäftszweck. Teams bauen Storage und Pipelines, bevor ein priorisierter Use Case, saubere Datenverantwortung und ein minimales Zielbild feststehen. Das Ergebnis ist oft viel Infrastruktur, aber wenig nutzbarer Output.
Am Anfang sind Datenmodellierung, Pipeline-Bau, Datenqualität und Systemintegration wichtiger als ein maximal breites Tool-Set. Ein kleines Team mit gutem Verständnis für Event-Design, Storage, Transformation und Betriebsfragen ist meist wirksamer als viele Personen mit isoliertem Spezialwissen.
Wenn ihr Big-Data-Themen nicht nur verstehen, sondern in eure bestehende Produktentwicklung integrieren wollt, kann PandaNerds euer Team mit sorgfältig geprüften Senior Developers verstärken. Ob Data Engineering, Backend, Cloud oder produktionsnahe Architektur, das Modell ist flexibel und passt sowohl zu MVPs als auch zu wachsenden Engineering-Organisationen.
































































































.svg)


