.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Ihre Lage ist wahrscheinlich vertraut: Es gibt Transaktionsdaten im Kernsystem, Event-Daten aus dem Produkt, Logs aus der Infrastruktur, vielleicht Telemetrie aus Geräten, dazu CSV-Exporte aus Fachbereichen und APIs von Drittsystemen. Die Datenmenge wächst, aber die eigentliche Frage bleibt offen: Welche Architektur bringt diese Daten zuverlässig in Entscheidungen, Automatisierung und operative Produkte?
Genau dort werden big data technologien relevant. Nicht als Schlagwort, sondern als Architekturdisziplin. Wer nur über Speicher spricht, verfehlt den Kern. Das eigentliche Problem ist, wie Daten aufgenommen, verarbeitet, qualitätsgesichert, bereitgestellt und kontrolliert werden, ohne dass jede neue Quelle das System fragiler macht.
Viele Teams setzen Big Data noch mit “sehr viel Speicher” gleich. In der Praxis ist das zu kurz gedacht. Das Problem beginnt meist nicht erst bei der Datenmenge, sondern dann, wenn unterschiedliche Datentypen mit unterschiedlicher Geschwindigkeit in dasselbe operative System gedrückt werden sollen.
IBM beschreibt Big Data als Datenbestände, deren Größe und Komplexität nur mit Machine Learning und vor allem verteilten Verarbeitungssystemen beherrschbar werden. Für CTOs ist der Hebel klar: Ohne Pipeline aus Ingestion, Storage, Processing und Consumption lassen sich wachsende Datenströme aus IoT, Produkttelemetrie oder Transaktionen nicht belastbar in Business-Entscheidungen überführen, wie IBM im Überblick zu Big Data und verteilten Verarbeitungssystemen beschreibt.
Ein klassisches OLTP-System ist für Transaktionen gebaut. Es ist nicht dafür gebaut, parallel Rohdaten aus vielen Quellen zu sammeln, historische Daten über lange Zeiträume aufzubereiten und gleichzeitig analytische Abfragen mit wechselnden Schemata zu bedienen.
Typische Symptome sind schnell erkennbar:
Praxisregel: Big Data beginnt dort, wo ein einzelnes System nicht mehr gleichzeitig zuverlässig speichern, transformieren, analysieren und bereitstellen kann.
In Deutschland wurde Big Data früh als Infrastrukturthema verstanden. Fachquellen verweisen auf die Verbreitung von Hadoop und verteilten Verarbeitungssystemen ab den 2010er-Jahren. Big Data wurde dabei nicht nur über Größe definiert, sondern auch über Geschwindigkeit und Vielfalt von Daten, die herkömmliche Datenbanken überfordern. Gerade Hadoop wurde als Schlüsseltechnologie zur Bewältigung dieser Massendaten beschrieben, wie die Einordnung bei Datasolut zu Big Data und Hadoop zeigt.
Für die technische Leitung ist das die entscheidende Perspektive. Sie kaufen kein Tool gegen “viel Daten”. Sie entwerfen ein System, das Last verteilt, Formate entkoppelt und Verarbeitungsschritte sauber trennt. Erst dann werden Daten verlässlich nutzbar.
Eine belastbare Datenplattform lässt sich besser als Folge von Schichten verstehen als als Tool-Sammlung. Das hilft bei Architekturentscheidungen deutlich mehr als jede Liste mit Trend-Technologien.

Eine Bitkom-Publikation gliedert die zentralen Verarbeitungsschichten von Big-Data-Systemen in vier Ebenen: Datenhaltung, Datenzugriff, analytische Verarbeitung und Visualisierung. Das ist nützlich, weil es Big Data nicht auf Storage reduziert, sondern als vollständige Infrastruktur für Geschäftsentscheidungen einordnet. Eine kompakte Darstellung dieser Schichten findet sich in der Erklärung zu Big Data als mehrschichtige Systemarchitektur.
Am Anfang steht die Ingestion. Hier geht es um die kontrollierte Aufnahme von Daten aus Datenbanken, APIs, Files, Sensoren oder Events. In der Praxis ist diese Schicht oft unterschätzt. Wenn sie schlecht entworfen ist, setzen sich Probleme später in jeder anderen Ebene fort.
Gute Ingestion trennt klar zwischen drei Fällen:
Bei der Speicherung folgt dann die wichtigste Architekturfrage: Brauchen Sie ein Warehouse, einen Data Lake oder eine Kombination daraus? Ein Warehouse ist stark für strukturierte, kuratierte Analysen. Ein Data Lake ist flexibler für Rohdaten, wechselnde Formate und spätere Verarbeitung. Viele Teams landen sinnvollerweise bei einer kombinierten Lakehouse- oder Mehrschichten-Architektur.
Die Verarbeitungsschicht transformiert Rohdaten in nutzbare Datenprodukte. Dort laufen SQL-Transformationen, Spark-Jobs, Streaming-Logiken, Feature-Berechnungen oder Qualitätsprüfungen. Das Entscheidende ist nicht das Tool, sondern das Betriebsmodell. Wer Transformationen nicht versioniert, testet oder überwacht, baut technische Schulden in die Datenplattform ein.
Später folgt die Serving-Schicht. Hier werden Ergebnisse konsumierbar: Dashboards, APIs, Reverse ETL, Suchindizes oder ML-Features. Viele Plattformen scheitern nicht an der Verarbeitung, sondern daran, dass die letzten Meter fehlen.
Eine gute Datenplattform optimiert nicht nur das Ablegen von Daten. Sie verkürzt den Weg von Rohdaten zu einer belastbaren Handlung.
Ein kurzes Architekturvideo als visuelle Ergänzung hilft beim Einordnen der Schichten:
Bewährt hat sich eine Architektur, in der Verantwortlichkeiten klar getrennt sind:
Was nicht funktioniert, ist ein Sammelsurium aus Einzeltools ohne Verantwortungsmodell. Dann gibt es zwar viele Komponenten, aber keine Plattform.
Die meisten Diskussionen über big data technologien entgleisen, weil Werkzeuge gegeneinander ausgespielt werden, obwohl sie unterschiedliche Probleme lösen. Hadoop, Spark und NoSQL sind keine direkten Ersatzprodukte. Sie besetzen verschiedene Rollen.

Ein guter technischer Vergleich beginnt deshalb nicht bei Benchmarks, sondern bei Einsatzmustern. Wer die Rollen sauber trennt, trifft bessere Entscheidungen. Eine vertiefende Einordnung der Unterschiede finden Sie auch im Vergleich Spark vs. Hadoop im Architekturkontext.
Hadoop ist vor allem historisch und architektonisch wichtig. Es hat verteilte Speicherung und Batch-Verarbeitung in vielen Unternehmen erst praktikabel gemacht. In bestehenden Plattformen spielt es noch immer eine Rolle, besonders dort, wo HDFS, MapReduce oder ältere Ökosysteme fest verankert sind.
Stärken von Hadoop:
Grenzen von Hadoop:
Apache Spark ist in vielen Teams der praktische Standard für Verarbeitung. Der Grund ist einfach: Es deckt Batch-Verarbeitung, interaktive Analysen und ML-nahe Workloads in einem Framework ab. Für Datenplattformen ist das oft der beste Kompromiss zwischen Flexibilität und Reife.
NoSQL-Datenbanken lösen ein anderes Problem. Sie sind kein Analyse-Framework, sondern spezialisierte Speichersysteme für Zugriffsmuster, bei denen relationale Modelle unpassend oder zu starr werden. Dokumentenmodelle, Key-Value-Zugriffe oder hohe Schreibraten sind typische Gründe.
Wer Spark als Datenbank behandelt, baut das falsche System. Wer NoSQL als Ersatz für eine analytische Plattform einführt, ebenso.
Die Frage lautet selten “Hadoop oder Spark oder NoSQL?”. Relevanter ist:
In vielen realen Plattformen koexistieren diese Technologien. Hadoop bleibt als Bestandssystem oder Storage-Baustein, Spark verarbeitet, NoSQL bedient transaktionsnahe oder produktnahe Use Cases. Probleme entstehen erst, wenn ein Team versucht, ein einzelnes Werkzeug zum Universalwerkzeug zu machen.
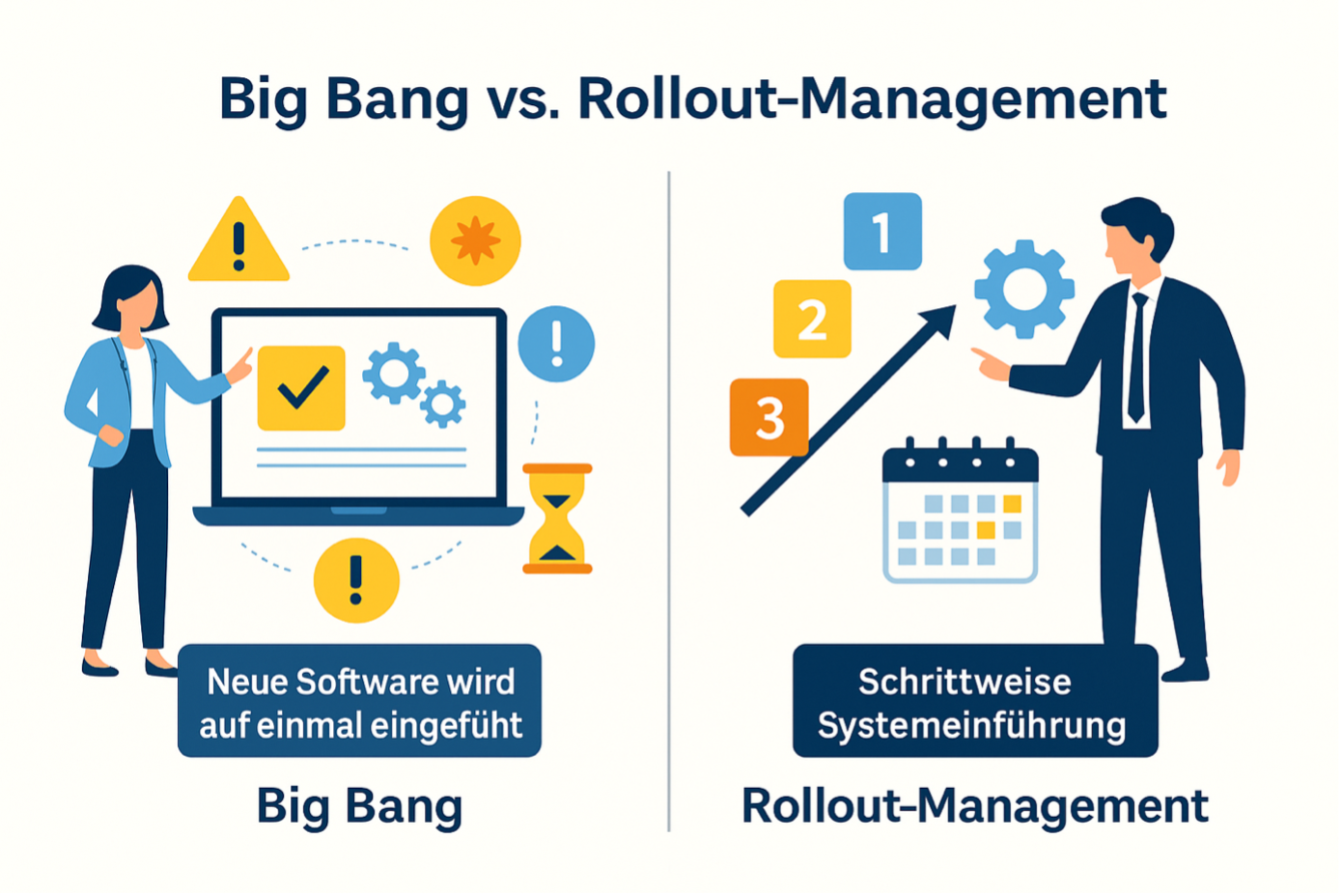
Die schwierigste Architekturentscheidung ist oft nicht die Tool-Wahl, sondern die Verarbeitungslogik. Viele Teams sagen vorschnell “wir brauchen Echtzeit”, obwohl der Business-Use-Case nur häufige Aktualisierung verlangt. Andere bleiben zu lange im Batch-Modell und merken erst spät, dass Latenz das Produkt ausbremst.
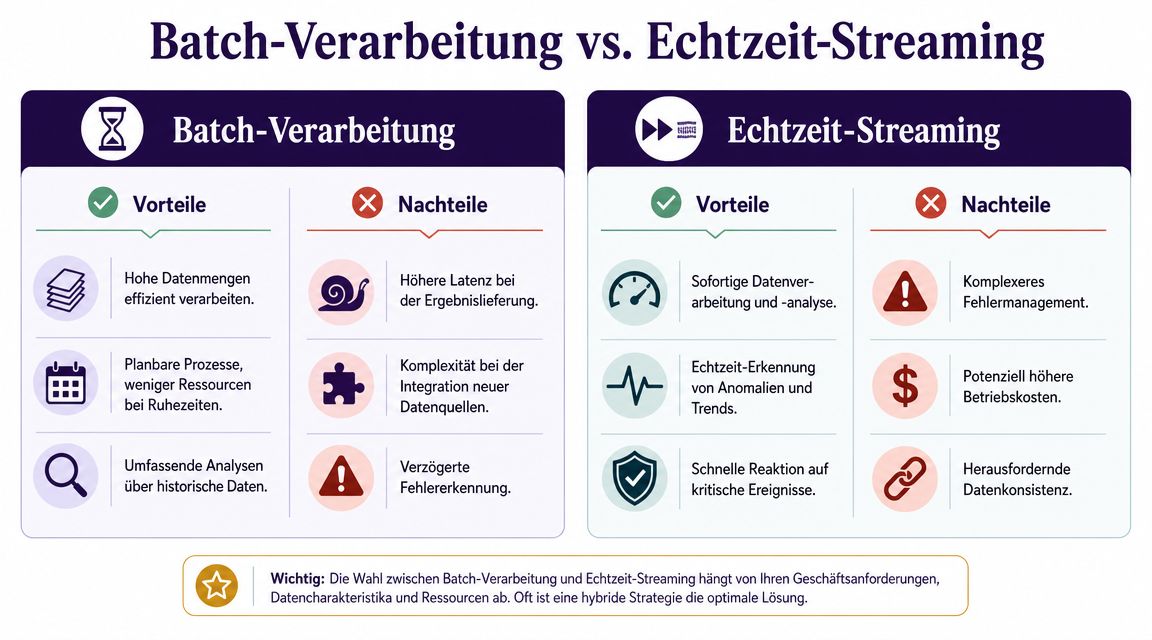
Batch ist oft zuverlässiger, günstiger zu betreiben und einfacher zu kontrollieren. Für klassische BI, periodisches Reporting, historische Trendanalysen oder nächtliche Datenaufbereitung ist Batch weiterhin das vernünftige Modell.
Batch passt gut, wenn:
Batch wird unterschätzt, weil es weniger modern wirkt. In vielen Unternehmen ist es aber die wirtschaftlichere Lösung.
Streaming lohnt sich dort, wo Entscheidungen ereignisnah getroffen werden müssen. Das betrifft etwa Web-Tracking, Zahlungsereignisse, Maschinenzustände oder operative Alerts. Für datenintensive Anwendungsfälle mit geringer Latenz sind Stream-Processing-Plattformen wie Apache Kafka ein Kernbaustein. Kafka reduziert die Kopplung zwischen Produzenten und Konsumenten und erlaubt Pufferung. Delta Lake stabilisiert als Storage-Layer mit Transaktionssicherheit die Datenqualität. Gerade für Teams mit Anforderungen an Nachvollziehbarkeit und versionierbare Datenzustände ist diese Kombination wertvoll, wie die technische Einordnung zu Apache Kafka, Delta Lake und Streaming-Architekturen zeigt.
Streaming ist kein Selbstzweck. Es lohnt sich erst dann, wenn die zusätzliche Komplexität direkt in geschäftlichen Nutzen übersetzt wird.
Die sauberste Entscheidung entsteht oft aus wenigen Fragen:
Was nicht funktioniert: Batch-Systeme künstlich auf “fast quasi real time” zu trimmen. Das erzeugt meist nur fragilen Taktbetrieb. Ebenso problematisch ist Streaming ohne klares Konsumentenmodell. Dann sammelt man Events, aber niemand übernimmt Ownership für Semantik und Qualität.
Die Auswahl von big data technologien ist eine strategische Basisentscheidung. Das weltweit jährlich produzierte Datenvolumen sollte sich laut SAP bis 2025 auf 163 Zettabyte verzehnfachen. Für 2028 prognostiziert Statista 394 Zettabyte. SAP beschreibt zudem, dass moderne Big-Data-Technologien Daten aus Quellen wie IoT-Geräten und sozialen Medien teils in Millisekunden verarbeiten können. Die Kombination aus Datenwachstum und Echtzeitfähigkeit macht Technologieauswahl zu einer Architekturfrage mit Langzeitwirkung, wie SAP im Überblick zu Big Data, Datenwachstum und Echtzeitverarbeitung darstellt.
Viele Fehlentscheidungen entstehen nicht durch schlechte Produkte, sondern durch falsche Annahmen. CTOs sollten vor jeder Auswahl mindestens diese Fragen beantworten:
Lizenzkosten sind nur ein Teil der Wahrheit. Im Alltag dominieren häufig andere Faktoren:
Ein häufiger Fehler ist die Auswahl einer technisch eleganten Lösung, die personell nicht tragfähig ist. Ein kleineres Team fährt mit weniger Komponenten oft besser, selbst wenn die Architektur auf dem Papier weniger “modern” wirkt.
Die richtige Plattform ist nicht die mit den meisten Funktionen. Es ist die, die Ihr Team in zwei Jahren noch beherrscht.
Viele Big-Data-Initiativen scheitern nicht in der Konzeptphase, sondern im Betrieb. Der Prototyp funktioniert. Der erste Fachbereich ist zufrieden. Dann kommen neue Quellen, strengere Zugriffsregeln, SLA-Erwartungen und die Frage, warum derselbe Job heute andere Ergebnisse liefert als letzte Woche.

Laut Bitkom nutzen viele Unternehmen Daten vor allem für Analysen, nicht für durchgängig operationalisierte Prozesse. 38% der deutschen Unternehmen setzen bereits KI ein. Das zeigt, wie groß die Lücke zwischen Analyse und produktiver Wertschöpfung noch ist, wie Bitkom in der Einordnung zu Big Data, KI-Nutzung und operationalisierten Prozessen beschreibt.
Sobald eine Plattform produktiv wird, zählen andere Dinge als im PoC. Dann geht es um Wiederholbarkeit, Governance und Fehlerverhalten.
Drei operative Disziplinen sind entscheidend:
Viele Teams überwachen Infrastruktur, aber nicht Daten. CPU, RAM und Clusterzustand sind sichtbar. Fehlende Events, Schema-Drift oder doppelte Datensätze oft nicht. Genau dort entstehen später Vertrauensprobleme bei Fachbereichen.
Ein zweites Muster ist fehlende Ownership. Wenn Ingestion, Transformation und Konsum auf verschiedene Teams verteilt sind, aber niemand Ende-zu-Ende-Verantwortung trägt, bleiben Fehler an den Schnittstellen liegen.
Wenn ein Dashboard falsch ist, interessiert niemanden, welches Teilteam technisch “nicht zuständig” war.
ROI in Big-Data-Plattformen misst man am besten pro Anwendungsfall, nicht als pauschalen Plattformwert. Sinnvoll sind qualitative und interne betriebliche Kriterien wie:
Was nicht funktioniert, ist ein generischer ROI-Slide ohne Baseline. Plattformen rechtfertigen sich dauerhaft nur dann, wenn sie operative Reibung senken und neue Datenprodukte schneller in Produktion bringen.
Wer big data technologien nur als Liste von Tools betrachtet, landet schnell in einer unübersichtlichen Plattform mit zu vielen Komponenten und zu wenig Wirkung. Der bessere Ansatz beginnt beim Geschäftsproblem. Erst danach folgt die Architektur.
Ein pragmischer Weg sieht meist so aus:
Die wichtigste Leitlinie ist einfach: Bauen Sie keine Datenplattform für denkbare Zukunftsszenarien. Bauen Sie eine Plattform, die ein reales Problem heute sauber löst und morgen kontrolliert erweitert werden kann.
Wenn Sie das konsequent tun, werden Big-Data-Technologien nicht zum Kostentreiber, sondern zur belastbaren Grundlage für Analytics, Automatisierung und datengetriebene Produkte.
Wenn Sie dafür kurzfristig erfahrene Unterstützung brauchen, kann PandaNerds Ihr Team mit sorgfältig geprüften Senior Engineers verstärken, die sich in bestehende Entwicklungs- und Datenplattformen einfügen, statt neue Reibung zu erzeugen. Das ist besonders hilfreich, wenn Architekturentscheidungen, Plattformbetrieb oder ein erster produktionsnaher PoC zügig umgesetzt werden müssen.
































































































.svg)


