.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Der Release ist terminiert, die wichtigsten User Flows funktionieren in Staging, und das Team ist müde. Genau in diesem Moment wird Cloud-Testing oft gefährlich oberflächlich. Ein paar API-Checks laufen grün, der Login klappt, vielleicht wurde noch ein schneller Cypress-Run durchgeklickt. Dann geht die Anwendung live und erst unter echter Last zeigen sich die Probleme: langsame Datenbankpfade, fragile Integrationen, Timeouts in Drittsystemen, falsch gesetzte Rechte oder Testdaten, die mit der Realität nichts zu tun hatten.
Ein umfassender Cloud App Test beginnt deshalb nicht bei einem Tool. Er beginnt mit der Frage, welche Risiken Ihre Anwendung im echten Betrieb tragen muss. Für einen SaaS-Workflow ist das etwas anderes als für ein internes B2B-Portal mit sensiblen Personendaten. In beiden Fällen gilt aber: Wer nur Features prüft, testet zu wenig. Wer nur automatisiert, ohne Architektur und Datenflüsse sauber zu modellieren, testet oft am Problem vorbei.
In Projekten mit deutschen KMUs sehe ich denselben Engpass immer wieder. Teams investieren früh in Testframeworks, aber zu spät in die strategischen Entscheidungen dahinter. Welche Pfade sind geschäftskritisch. Welche Lastprofile sind realistisch. Welche Daten dürfen überhaupt in Testumgebungen landen. Und welche Szenarien müssen Senior-Entwickler vorab architektonisch absichern, bevor irgendein Skript Mehrwert liefert.
Kurz vor dem Go-live wirkt vieles stabil, weil die Anwendung in einer kontrollierten Umgebung läuft. Die Requests sind berechenbar, die Datenmenge überschaubar, und kaum jemand provoziert Grenzfälle. Produktion verhält sich anders. Nutzer kommen gleichzeitig, Integrationen antworten ungleichmässig, Caches sind kalt, und plötzlich wird aus einem sauberen Demo-Flow ein Engpass im Betrieb.
Die riskanteste Annahme lautet dann: „Wir haben doch getestet.“ Gemeint sind oft Funktionstests gegen Happy Paths. Das reicht für Cloud-Anwendungen selten aus. Eine moderne Webanwendung hängt an APIs, Message Queues, Datenbanken, Identity-Providern und Infrastrukturkonfigurationen. Wenn nur eine dieser Ebenen unter Last kippt, merkt der Nutzer davon zuerst nur eines. Die App wirkt langsam oder unzuverlässig.
"Cloud-Testing scheitert selten an fehlenden Tools. Es scheitert daran, dass Teams zu spät definieren, was überhaupt als „bestanden“ gilt."
Praktisch heisst das: Sie brauchen nicht mehr Tests um jeden Preis. Sie brauchen die richtigen Tests, in der richtigen Reihenfolge, mit klaren Abbruchkriterien. Ein Checkout-Flow, ein Mandantenwechsel, ein Datei-Upload oder eine Rollenänderung sind keine gleichwertigen Szenarien. Manche Pfade kosten bei Fehlern nur Zeit. Andere kosten Vertrauen, Umsatz oder Compliance-Sicherheit.
Dazu kommt ein Punkt, den viele Anleitungen ausblenden. In der Cloud ist Testen auch eine Kostenfrage. Dauerhaft laufende Staging-Umgebungen, schlecht geschnittene Lasttests und unkontrollierte Testdatenhaltung treiben Budgets schnell hoch. Gute Teams planen Qualitätssicherung deshalb zusammen mit Infrastruktur und Betrieb. Nicht danach.
Wenn Sie Ihren Cloud App Test sauber aufsetzen, gewinnen Sie drei Dinge gleichzeitig: bessere Releases, weniger operative Überraschungen und eine belastbare Grundlage für Skalierung. Der Rest dieses Leitfadens folgt genau diesem Pfad. Erst die Strategie, dann die Testdisziplinen, dann Infrastruktur, Monitoring und die Frage, wie man fehlende Senior-Expertise realistisch kompensiert.
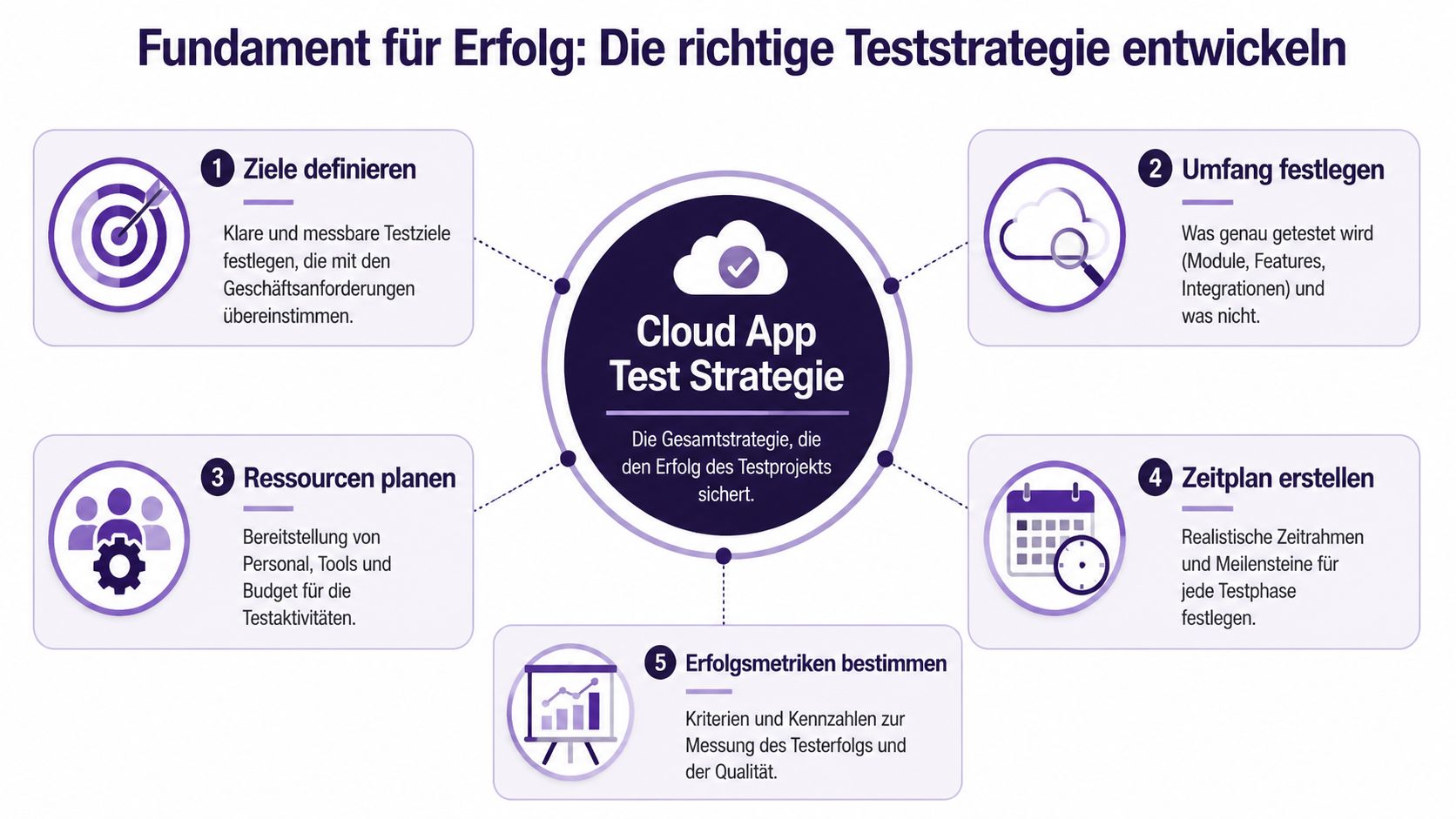
Ein guter Testprozess startet nicht mit Playwright, Cypress, k6 oder JMeter. Er startet mit Entscheidungen. Wenn diese Entscheidungen fehlen, wird selbst ein sauber automatisierter Teststack teuer und unzuverlässig.
Für Cloud-Performance-Tests zählen vor allem Response Time, Latenz, Throughput, Error Rates und Ressourcenauslastung. In der Praxis werden diese Kennzahlen den Zielen Speed, Scalability und Reliability zugeordnet, wie der Beitrag zu Cloud Performance Testing von TestingXperts beschreibt.
Das ist ein wichtiger Startpunkt, weil er Diskussionen erdet. Ein Team, das „die App muss schnell sein“ sagt, hat noch keine testbare Anforderung formuliert. Ein Team, das kritische Transaktionen, tolerierbare Fehlerraten und beobachtbare Ressourcenengpässe benennt, kann ein belastbares Testdesign bauen.
Viele Teams testen entweder zu breit oder zu romantisch. Zu breit heisst: Alles wird gleich wichtig behandelt. Zu romantisch heisst: Man entwirft ein vollständiges Testuniversum, das nie fertig wird.
Hilfreicher ist eine knappe Einteilung:
Gerade bei deutschen Anwendungen sollte der Scope explizit festhalten, welche Tests DSGVO-relevante Datenflüsse berühren. Sonst landen Datenschutzfragen zu spät im Prozess und blockieren kurz vor dem Release.
Wenn Budget und Zeit knapp sind, gewinnt nicht der breiteste Testkatalog. Es gewinnt die beste Priorisierung.
"Praxisregel: Definieren Sie pro kritischem Pfad eine fachliche Erwartung, eine technische Metrik und ein klares Fehlersignal. Erst dann lohnt sich Automatisierung."
Eine Teststrategie scheitert oft nicht fachlich, sondern organisatorisch. Wenn niemand für Testdaten, Umgebungen oder flakey Builds verantwortlich ist, entsteht Reibung in jeder Iteration. Deshalb braucht auch ein kleiner Cloud App Test einen Betriebsmodus.
Dazu gehört ein Rhythmus aus schnellen Prüfungen pro Commit, breiteren Integrationsprüfungen auf Merge-Ebene und schwereren Last- oder Sicherheitsläufen nach Plan. Wer Continuous Integration ernst nimmt, baut diese Schichten bewusst auf. Eine kompakte Einordnung dazu finden Sie bei PandaNerds unter Was ist Continuous Integration.
Cloudbasierte Testumgebungen gelten gegenüber lokalen Setups als vergleichsweise kostengünstig. Das begünstigt ihren Einsatz in Startups und im Mittelstand, aber nur dann, wenn Umgebungen nicht unkontrolliert weiterlaufen und Tests nicht wahllos skaliert werden. Die Strategie entscheidet also nicht nur über Qualität, sondern direkt über Ihre Cloud-Rechnung.
Cloud-Anwendungen brechen selten an einer einzigen Stelle. Sie brechen an den Übergängen. Zwischen Frontend und API. Zwischen Service und Datenbank. Zwischen Identity-Layer und Rollenmodell. Deshalb muss Ihr Testmodell mehrere Disziplinen abdecken, die sich gegenseitig absichern.
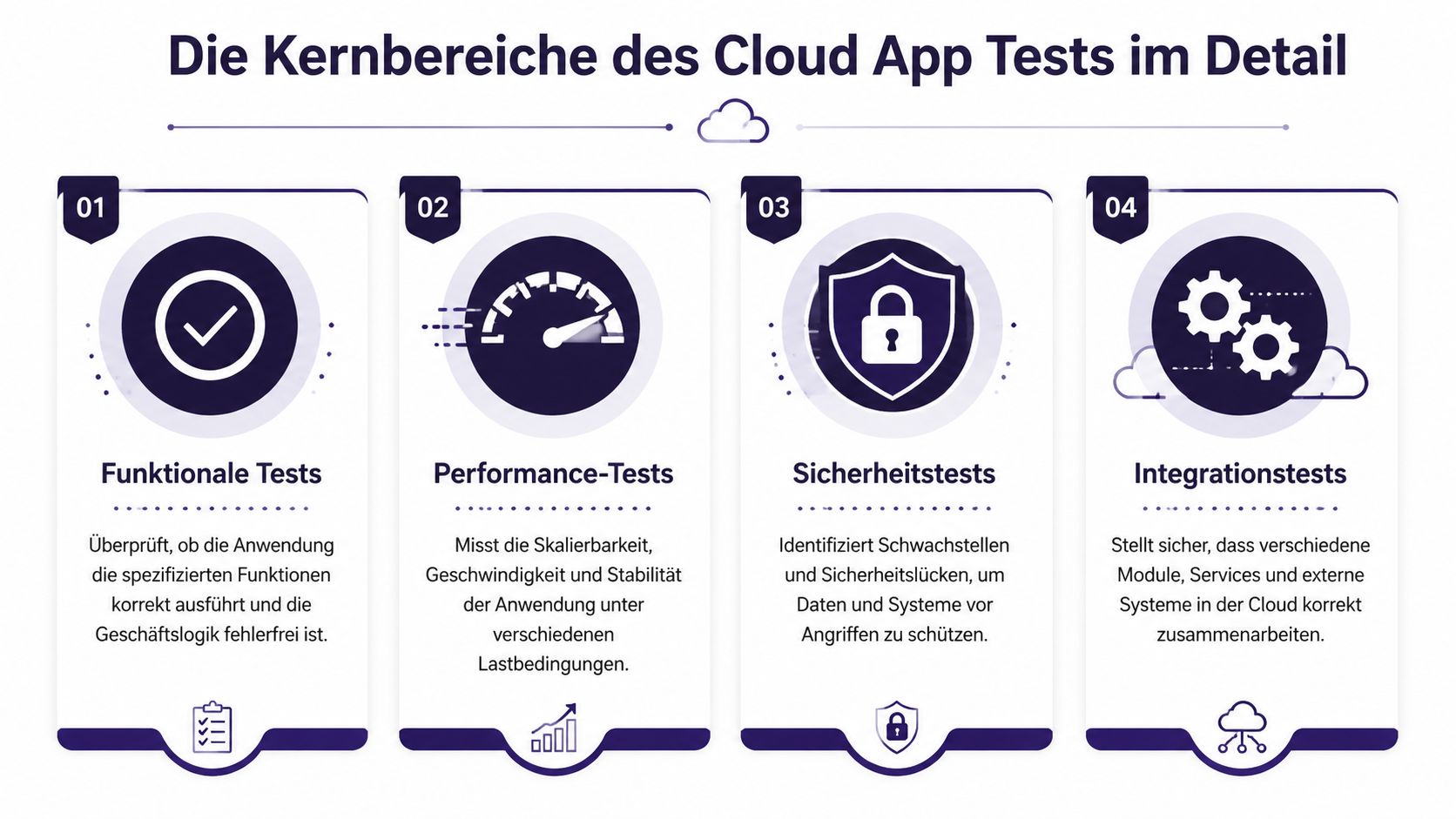
Funktionale Tests beantworten die simpelste und zugleich wichtigste Frage: Tut die Anwendung das, was sie fachlich tun soll?
Hier geht es nicht nur um Klickpfade im Browser. Gute funktionale Tests prüfen Validierung, Zustandswechsel, Fehlerszenarien und Berechtigungen. Ein einfacher Buchungsworkflow ist fachlich erst dann abgesichert, wenn auch doppelte Requests, abgelaufene Sessions und ungültige Übergaben geprüft werden.
Was in echten Projekten funktioniert:
Was oft nicht funktioniert, ist eine übergrosse UI-Suite. Wenn Hunderte Browser-Tests die Basis bilden, leidet die Wartbarkeit zuerst.
Integrationstests sind in Cloud-Systemen oft wertvoller als zusätzliche Unit-Tests. Der Grund ist einfach. Viele Produktionsfehler entstehen nicht in isolierter Logik, sondern im Zusammenspiel von Komponenten.
Typische Kandidaten sind OAuth-Flows, Payment-Provider, E-Mail-Dienste, Object Storage, Suchindizes und Message Broker. Gerade bei asynchronen Systemen sollten Sie nicht nur „kommt eine Nachricht an?“ testen, sondern auch Retries, Idempotenz und Fehlerpfade.
Ein guter Integrationstest simuliert nicht nur den Sonnenscheinfall. Er prüft auch, was passiert, wenn ein Drittsystem langsam antwortet oder unerwartete Fehler liefert.
Bei Performance-Tests wird besonders oft zu grob gearbeitet. Ein einzelner Lastlauf mit ein paar Durchschnittswerten sieht sauber aus, sagt aber wenig über die tatsächliche Stabilität Ihrer Anwendung.
Die PT4Cloud-Methode zeigt einen reiferen Ansatz. Anwendungen werden in mehreren Zeitintervallen wiederholt ausgeführt, bis sich die geschätzte Performance-Verteilung nicht mehr signifikant verändert. Laut der wissenschaftlichen Beschreibung erreicht das Verfahren eine durchschnittliche Genauigkeit von 95,4 % und liegt in allen Fällen über 90 %, bei geringerem Testaufwand als umfangreiche Benchmark-Läufe. Nachzulesen ist das in der Studie PT4Cloud.
Für die Praxis ist daran weniger die Zahl interessant als die Methode. Gute Lasttests basieren auf Verteilungen, Konfidenzintervallen und Signifikanz. Schlechte Lasttests produzieren nur schöne Grafiken.
"Wenn Ihr Lasttest nur eine mittlere Antwortzeit ausspuckt, fehlt Ihnen wahrscheinlich genau die Information, die später den Betrieb kippen lässt."
Sicherheitstests sind kein Scan-Lauf am Ende des Sprints. Sie beginnen bei Rollenmodell, Secrets-Handhabung, Netzwerkgrenzen und Konfiguration.
Automatisierte Scanner helfen bei bekannten Schwachstellen. Sie ersetzen aber nicht die fachliche Frage, ob ein Benutzer zu viel sieht, ob ein Token zu lange gilt oder ob ein interner Service unbeabsichtigt von aussen erreichbar ist. Besonders in Cloud-Umgebungen gehören deshalb Konfigurationsprüfungen, Rechteprüfungen und Architektur-Reviews zwingend dazu.
Wenn Sie den Sicherheitsanteil Ihres Teststacks vertiefen wollen, ist der Überblick zu Security Testing ein sinnvoller Einstieg.
Viele Testprobleme sind in Wahrheit Infrastrukturprobleme. Nicht der Testfall ist falsch, sondern die Umgebung instabil, die Daten unbrauchbar oder die Pipeline zu langsam. Wer das ignoriert, produziert flakey Ergebnisse und verliert Vertrauen in den gesamten Quality-Stack.
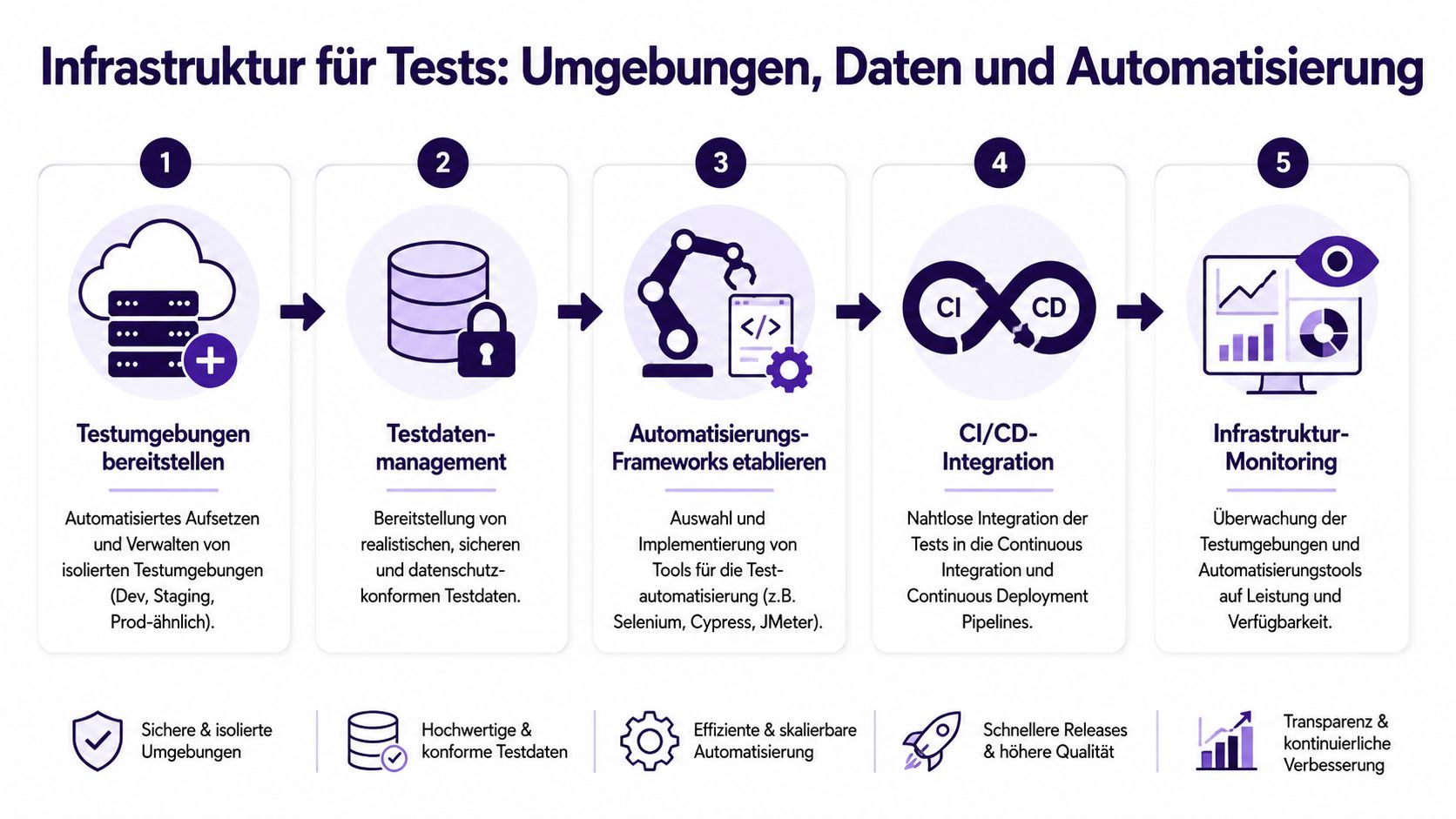
Ein häufiger Fehler ist die Wahl zwischen zwei Extremen. Entweder gibt es nur eine langlebige Staging-Umgebung, in der alles gleichzeitig passiert. Oder jede Testart bekommt ihre eigene, teuer betriebene Vollkopie der Produktion.
Pragmatischer ist ein gestuftes Modell:
In Kubernetes-Setups funktionieren Namespaces oder kurzlebige Review Environments gut. In einfacheren Architekturen reichen oft klar getrennte Deployments mit reproduzierbarer Provisionierung. Wichtig ist nicht Perfektion. Wichtig ist, dass jede Umgebung einen klaren Zweck hat.
Eine saubere Einordnung cloud-nativer Betriebsmodelle hilft dabei, besonders wenn Ihr Team zwischen klassischen und dynamischen Umgebungen pendelt. Ein verständlicher Einstieg ist Cloud nativ einfach erklärt.
Testdaten werden gern als Nebensache behandelt. Spätestens bei Datenschutz, Reproduzierbarkeit und Fehlersuche zeigt sich das Gegenteil.
Für die Praxis haben sich zwei Modelle bewährt:
Für deutsche KMUs ist das Thema besonders heikel. Wer mit personenbezogenen Daten arbeitet, sollte Testdaten nicht nur technisch, sondern organisatorisch absichern. Das umfasst Herkunft, Transformation, Aufbewahrung und Löschung. Wenn das nicht dokumentiert ist, wird jeder spätere Audit unangenehm.
"Gute Testdaten bilden nicht nur das Schema ab. Sie bilden auch die Fehler, Lücken, Sonderfälle und historischen Altlasten ab, die Ihre echte Anwendung aushalten muss."
Automatisierung ist dann nützlich, wenn sie schnell Rückmeldung gibt und Teams nicht mit Rauschen überflutet. Die meisten Pipelines werden besser, wenn sie bewusst in Schichten aufgeteilt werden.
Bei den Tools gilt keine Einheitslösung. Playwright oder Cypress sind stark für Browser-Flows. Postman oder reine API-Testframeworks eignen sich für Service-Validierung. k6 oder JMeter helfen bei Lastprofilen. Terraform oder Pulumi sorgen dafür, dass Testumgebungen reproduzierbar bleiben.
Was nicht funktioniert, ist ein einziger grosser Pipeline-Block, der jede Änderung mit allen Testarten belegt. Das verlängert Feedback-Zyklen und lädt dazu ein, Tests zu umgehen. Ein belastbarer Cloud App Test ist deshalb nicht nur automatisiert. Er ist sinnvoll getaktet.
Nach dem Deployment beginnt die eigentliche Bewährungsprobe. Vorher testen Sie Annahmen. Danach beobachten Sie Verhalten. Wer diese beiden Phasen sauber verbindet, bekommt nicht nur stabilere Releases, sondern auch bessere Entscheidungen über Kosten, Kapazitäten und Prioritäten.
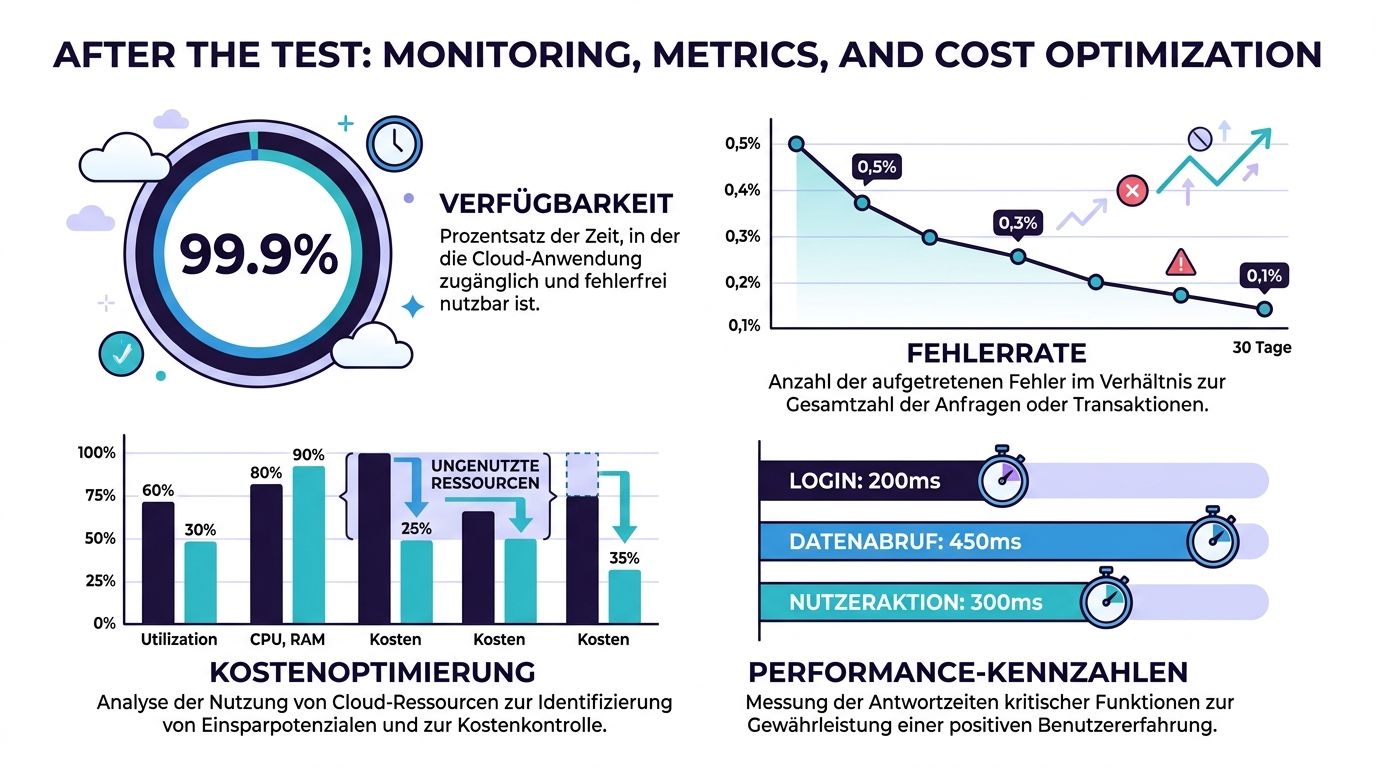
Wenn Sie im Test auf Antwortzeiten, Fehlerraten und Ressourcennutzung optimieren, sollten genau diese Signale später im Betrieb sichtbar sein. Sonst fehlt die Verbindung zwischen Vorhersage und Realität.
In der Praxis heisst das:
Prometheus und Grafana sind dafür ein solides Standard-Setup. In stärker gemanagten Umgebungen greifen Teams oft zu Datadog oder Cloud-eigenen Monitoring-Diensten. Entscheidend ist nicht das Tool, sondern die Disziplin, aus Dashboards betriebliche Entscheidungen abzuleiten.
Viele Teams betrachten Testkosten separat von Betriebsdaten. Das ist ein Fehler. Wenn Monitoring zeigt, dass bestimmte Lastläufe kaum neue Erkenntnisse liefern, können Sie Frequenz, Umfang oder Umgebungsgrösse anpassen. Wenn eine Staging-Umgebung nachts ungenutzt läuft, ist das kein Infrastrukturdetail, sondern verschwendetes Testbudget.
Sinnvolle Hebel sind:
Ein gutes Beispiel für den Wert betrieblicher Transparenz sieht man auch ausserhalb klassischer SaaS-Produkte. In Domänen mit operativer Steuerung, etwa beim Fahrzeugbestand, hängt die Qualität von Software direkt an der Sichtbarkeit von Kennzahlen und Wartezeiten. Wer dafür eine praxisnahe Referenz sucht, findet in der Managementlösung für den Fahrzeughandel ein gutes Beispiel dafür, wie Prozesse, Statusdaten und operative Entscheidungen zusammenspielen.
Die besten Teams behandeln Monitoring nicht als Kontrollinstrument nach dem Launch, sondern als Input für den nächsten Testzyklus. Wenn Produktionsdaten zeigen, dass ein bestimmter Endpoint unter Last anders reagiert als erwartet, gehört genau dieses Muster in den nächsten Lasttest. Wenn Alarme wiederholt auf dieselbe Integrationsschwäche hinweisen, muss der Integrationstest härter werden.
So entsteht aus Testing und Monitoring kein doppelter Aufwand, sondern ein Kreislauf. Genau dort sinken langfristig sowohl Risiko als auch unnötige Cloud-Kosten.
Viele deutsche KMUs stehen heute an einem unbequemen Punkt. Die Cloud-Nutzung ist längst Realität, aber die interne Senior-Kapazität für solide Testarchitekturen fehlt oft genau dann, wenn die Anwendung skaliert oder regulatorisch heikel wird.
Die Lage ist nicht nur ein Recruiting-Thema. Laut den vorgegebenen Marktdaten leiden in Deutschland 42 % der Unternehmen unter einem akuten Mangel an Senior-IT-Experten, was für 85 % der Verzögerungen in der Produktentwicklung verantwortlich ist. Gleichzeitig nutzen 78 % der deutschen KMUs Cloud-Infrastrukturen, aber nur 34 % haben die internen Ressourcen für ein DSGVO-konformes Testing. Diese Angaben stammen aus dem vorgegebenen Datenrahmen des Briefings.
Ein Tool kann Tests ausführen. Es kann keine tragfähige Testarchitektur entwerfen. Genau daran scheitern viele Teams.
Senior-Entwickler bringen in diesem Kontext drei Dinge ein, die Automatisierung allein nicht liefert:
Besonders bei DSGVO-relevanten Anwendungen reicht es nicht, Scanner und Pipeline-Jobs zu konfigurieren. Jemand muss entscheiden, welche Daten in welche Umgebung dürfen, wie Löschpfade geprüft werden und wo Data Sovereignty technische Folgen für Infrastruktur und Tests hat.
Ein mittelständisches Produktteam braucht nicht zwingend sofort ein komplett neues internes Senior-Team. In vielen Fällen ist ein schlankeres Modell vernünftiger. Externe Senior-Entwickler oder Architekten definieren Teststrategie, Guardrails und kritische Automatisierungspfade. Das interne Team setzt diese Vorgaben im Alltag um und betreibt sie weiter.
Das funktioniert besonders gut in Phasen wie:
"Ein erfahrener Senior spart nicht nur Implementierungszeit. Er verhindert, dass das Team monatelang das Falsche automatisiert."
Die eigentliche Stärke externer Expertise liegt also nicht darin, Tickets schneller abzuarbeiten. Sie liegt darin, den Testansatz auf ein Niveau zu bringen, auf dem Automatisierung überhaupt verlässlich wird. Gerade für deutsche SMEs ist das oft der Unterschied zwischen einem Test-Stack, der Vertrauen schafft, und einem, der nur Aktivität simuliert.
Ein belastbarer Cloud App Test ist kein einmaliger Sprint vor dem Release. Er ist ein Betriebsmodell. Gute Teams verbinden Strategie, Testarten, Infrastruktur, Monitoring und Kostensteuerung so, dass jede Schicht die nächste stützt. Dann entstehen weniger Überraschungen im Go-live und weniger teure Blindflüge danach.
Die wichtigste praktische Erkenntnis lautet: Testqualität entsteht nicht durch möglichst viele Skripte. Sie entsteht durch klare Prioritäten, realistische Umgebungen, brauchbare Daten und Senior-Entscheidungen an den kritischen Stellen.

Für die Projektpraxis genügt oft diese kurze Checkliste:
Wenn Ihr Team diese Punkte ehrlich durchgeht, sehen Sie meist sehr schnell, wo Ihr Cloud-Testing wirklich stark ist und wo nur Gewohnheit mitläuft.
Wenn Sie für genau solche Engpässe erfahrene Unterstützung brauchen, ist PandaNerds eine sinnvolle Adresse. Das Team unterstützt Unternehmen dabei, Senior-Developer gezielt in bestehende Produkt- und Engineering-Teams zu integrieren, besonders dann, wenn Architektur, Teststrategie und Skalierung nicht mehr sauber allein mit Tools lösbar sind.
































































































.svg)


