.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

In vielen wachsenden Unternehmen beginnt IT-Support harmlos. Ein Passwort funktioniert nicht, das VPN bricht ab, ein neues Gerät muss eingerichtet werden. Also schreibt jemand dem Entwickler direkt bei Slack, ruft kurz im Büro rüber oder leitet eine E-Mail an “denjenigen, der sich auskennt” weiter.
Am Anfang wirkt das schnell. Mit jedem neuen Mitarbeitenden wird es chaotischer.
Plötzlich lösen Senior-Entwickler Druckerprobleme, Product Manager jagen Status-Updates hinterher, und niemand kann sauber sagen, welche Störungen häufig auftreten, wie lange sie dauern oder warum sie immer wiederkommen. Genau an diesem Punkt wird helpdesk it support zu einem Führungs- und Skalierungsthema, nicht nur zu einer operativen Nebenaufgabe.
Für CTOs und Gründer in Deutschland ist die eigentliche Frage deshalb nicht, ob Support organisiert werden sollte. Die Frage ist: Welches Support-Modell passt zur eigenen Phase, Teamstruktur und Wachstumsrealität?
Ein unstrukturierter Supportprozess kostet selten nur Zeit. Er zieht Aufmerksamkeit aus dem Kernteam ab.
Wenn Anfragen per E-Mail, Chat, Zuruf und Direktnachricht gleichzeitig hereinkommen, entsteht kein verlässlicher Support, sondern ein informelles Störungsmanagement. Das Unternehmen reagiert dann nur noch auf Dringlichkeit. Nicht auf Priorität.

Ein typisches Muster in Scale-ups sieht so aus:
Ein professioneller Helpdesk schafft genau hier Ordnung. Er bündelt Anfragen, priorisiert sie, dokumentiert Lösungen und verteilt Arbeit nach Zuständigkeit. Das klingt banal, ist aber operativ entscheidend. Erst damit entsteht ein System, das auch unter Wachstum stabil bleibt.
Viele Gründer setzen Helpdesk mit einem Postfach oder einer Hotline gleich. Das greift zu kurz.
Ein funktionierender Helpdesk ist die operative Schicht zwischen Endnutzer und Technikteam. Er sorgt dafür, dass Störungen strukturiert aufgenommen, kategorisiert, bearbeitet und bei Bedarf eskaliert werden. Das schützt nicht nur Mitarbeitende vor Frust, sondern auch Ihr Engineering-Team vor permanentem Kontextwechsel.
"Praxisregel: Wenn produktnahe Entwickler regelmässig Alltagsstörungen lösen, fehlt Ihnen kein “mehr Einsatz”, sondern ein klares Support-Betriebsmodell."
Der Markt zeigt, dass Unternehmen Helpdesk-Strukturen längst nicht mehr als Randthema behandeln. Der globale Help-Desk-Support-Markt wurde 2024 auf 3.471,3 Millionen USD bewertet und soll laut Grand View Research bis 2030 auf 5.822,1 Millionen USD wachsen, bei einer prognostizierten CAGR von 9,2 Prozent. Im selben Datensatz wird auch genannt, dass 60 Prozent der schnell wachsenden Customer-Service-Teams bereits ein Help-Desk-System nutzen.
Für CTOs ist die Kernaussage klar. Strukturierter Support ist kein Verwaltungsaufwand. Er ist eine Voraussetzung dafür, dass Teams liefern können, ohne von operativen Kleinstörungen ausgebremst zu werden.
Wer helpdesk it support aufbauen oder einkaufen will, muss zuerst die Ebenen des Supports sauber trennen. Sonst besetzen Sie Rollen falsch, überfordern Mitarbeitende oder bezahlen Spezialisten für Aufgaben, die deutlich einfacher gelöst werden könnten.
Ein gutes Bild dafür ist die Notaufnahme im Krankenhaus. Nicht jeder Fall braucht sofort einen Spezialisten. Zuerst kommt die Einschätzung, dann die passende Weiterleitung, dann die tiefere Behandlung.
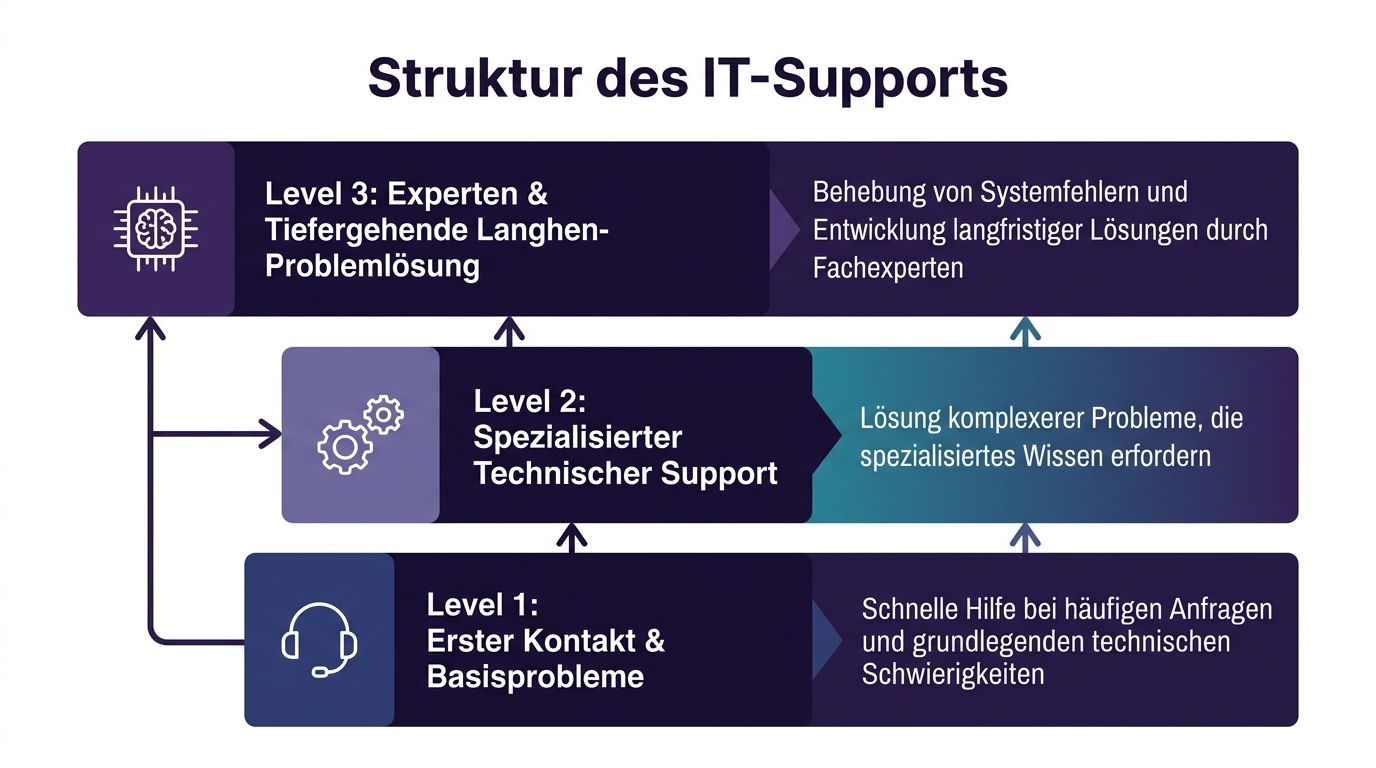
Level 1 ist der Eingangsbereich des Supports. Hier landen die meisten Anfragen zuerst.
Typische Fälle sind Passwort-Resets, Zugriffsprobleme, Standardfehler in Microsoft 365, einfache Hardwarefragen oder bekannte VPN-Probleme. L1-Mitarbeitende brauchen kein tiefes Entwicklerwissen, aber sie müssen sauber triagieren, ruhig kommunizieren und nach klaren Runbooks arbeiten.
Gute L1-Arbeit entscheidet oft darüber, ob ein Support-Team effizient bleibt. Wenn dieser erste Filter schwach ist, landet zu viel bei L2 oder L3. Dann steigen Wartezeiten und Spezialisten arbeiten an Routinefällen.
Wer die operative Basis dieses Einstiegs besser einordnen will, findet unter https://www.pandanerds.com/news/first-level-support eine gute Einordnung der typischen Aufgaben im First-Level-Support.
Level 2 übernimmt Tickets, die mehr technische Tiefe brauchen.
Hier geht es oft um Dinge wie fehlerhafte VPN-Konfigurationen, Rechteprobleme in Active Directory oder Azure AD, Patch-Probleme unter Windows, Geräteverwaltung, komplexere Netzwerkstörungen oder Softwarekonflikte, die sich nicht mit Standardantworten lösen lassen.
L2 braucht meist Menschen mit breiter Systemerfahrung. Sie lesen Logs, prüfen Abhängigkeiten, testen Konfigurationen und erkennen Muster, die im ersten Kontakt nicht sichtbar waren. In vielen KMU ist diese Ebene der eigentliche Engpass, weil sie operative Erfahrung und strukturiertes Troubleshooting zugleich verlangt.
Level 3 bearbeitet die Fälle, bei denen die eigentliche Ursache in Architektur, Code, Infrastrukturdesign oder Herstellerabhängigkeiten liegt.
Beispiele sind ein Bug in einer internen Anwendung, ein Problem im Identity-Management-Setup, eine fehlerhafte Integration zwischen Diensten oder eine Störung, die nur unter bestimmten Last- oder Konfigurationsbedingungen auftritt. L3 arbeitet oft eng mit Engineering, DevOps, Security oder externen Herstellern zusammen.
Diese Ebene löst nicht nur akute Tickets. Sie verhindert auch Wiederholungen, weil sie Root Causes beseitigt.
Im Alltag werden beide Begriffe oft vermischt. Praktisch lohnt sich die Trennung.
Ein Helpdesk beantwortet in erster Linie Probleme. Ein Service Desk betrachtet IT stärker als organisierte Dienstleistung, oft entlang von ITIL-Prinzipien. Für kleinere Unternehmen beginnt der Weg meist beim Helpdesk. Mit wachsender Reife entwickelt sich daraus häufig ein Service-Desk-Modell.
Diese Aufteilung ist nicht zufällig entstanden. Laut HDI entstand der moderne Service Desk 1988 mit der Gründung der Help Desk User Group. In den 1990er Jahren machten Remote-Support-Tools Fernwartung praktisch nutzbar. Das verkürzte Reaktionszeiten deutlich und legte die Grundlage für heutigen 24/7-Support. Helpdesks bearbeiteten damals bereits zwischen 1.500 und 3.000 Anfragen pro Monat.
Die Lehre daraus ist simpel. Support wurde professioneller, weil Unternehmen nicht mehr alles von denselben Personen bearbeiten lassen konnten. Diese Logik gilt heute genauso. Nur die Tools sind moderner geworden.
Sobald ein Support-Team steht, taucht die nächste Frage auf: Woran erkennen Sie, ob es gut arbeitet?
Viele Unternehmen messen zuerst das Falsche. Sie schauen nur auf Ticketmenge oder reine Reaktionszeit. Das reicht nicht. Gute Support-Steuerung verbindet operative Kennzahlen mit geschäftlicher Wirkung.

Die First Contact Resolution Rate, kurz FCR, zeigt, wie viele Anfragen bereits beim ersten Kontakt gelöst werden. Für CTOs ist diese Kennzahl besonders wertvoll, weil sie direkt auf Prozessqualität, Wissensstand und Routing hinweist.
In deutschen KMU liegt die durchschnittliche FCR bei 68 Prozent, und BeyondTrust verweist darauf, dass jede nicht beim ersten Kontakt gelöste Anfrage die Nachbearbeitungszeit um 45 Prozent erhöht und die Gesamtkosten pro Ticket um bis zu 32 Euro steigern kann. Im selben Kontext wird genannt, dass ITIL-konforme Prozesse die FCR auf über 85 Prozent steigern und die MTTR deutlich senken können.
Das ist geschäftlich relevant. Wenn L1 zu wenig lösen kann, wandern Tickets tiefer ins System. Das blockiert Spezialisten und verlängert die Zeit bis zur echten Problemlösung.
Nicht jede Metrik ist gleich wichtig. Für die operative Führung haben sich vor allem diese Kennzahlen bewährt:
Wichtig ist die Kombination. Eine niedrige Bearbeitungszeit bei schlechter Lösungsqualität bringt wenig. Genauso ist eine hohe FCR wertlos, wenn Nutzer unklare oder unfreundliche Antworten erhalten.
"Praktischer Blickwinkel: Messen Sie nie nur Geschwindigkeit. Messen Sie, ob das Team schnell, sauber und nachhaltig löst."
Service Level Agreements, kurz SLAs, definieren, wie schnell auf ein Ticket reagiert und in welchem Zeitraum es bearbeitet oder gelöst werden soll. Sie sind keine juristische Dekoration. Sie schaffen Prioritätslogik.
Ein sinnvolles SLA unterscheidet nach Tickettyp. Ein gesperrter Account im Vertrieb braucht eine andere Reaktionszeit als eine Frage zur Monitorbestellung. Gute SLAs beschreiben deshalb mindestens:
Viele Teams scheitern nicht an fehlender Leistung, sondern an unklaren Erwartungen. Genau dafür sind SLAs da.
Ein guter Einstieg in die operative Perspektive auf Kennzahlen und Servicequalität ist dieses kurze Video:
Drei Fehler sehe ich in der Praxis ständig:
Wenn Sie Support professionell führen wollen, brauchen Sie also nicht möglichst viele Kennzahlen. Sie brauchen die wenigen richtigen, sauber definiert und regelmässig überprüft.
Die Grundsatzentscheidung beim helpdesk it support lautet oft: selbst aufbauen oder extern einkaufen.
Beide Modelle funktionieren. Beide haben klare Grenzen. Die bessere Wahl hängt weniger von Ideologie ab als von Ihrer Teamgrösse, Ihrem Sicherheitsbedarf, Ihrer Prozessreife und davon, wie schnell Sie skalieren müssen.
In Deutschland ist die Inhouse-Option schwieriger geworden als viele Businesspläne annehmen. Laut Nexustek mit Verweis auf Bitkom fehlen der deutschen IT-Branche rund 149.000 Fachkräfte, 73 Prozent der IT-Profis empfinden ihre Abteilungen als unterbesetzt, und 62 Prozent der Unternehmen outsourcen Helpdesk-Aufgaben, um den Betrieb aufrechtzuerhalten.
Für Gründer und CTOs heisst das praktisch: Selbst wenn Sie Inhouse wollen, können Recruiting-Zeit, Gehaltsniveau und operative Last den Aufbau stark verzögern.
Ein internes Team passt gut, wenn Ihr Unternehmen hohe Anforderungen an Nähe, Kontext und interne Abstimmung hat.
Das gilt besonders, wenn Support eng mit Produktentwicklung, Security, Compliance oder internen Spezialprozessen verzahnt ist. Ein Inhouse-Team baut mit der Zeit viel Organisationswissen auf. Es kennt Ihre Menschen, Ihre Tools, Ihre Schattenprozesse und Ihre gewachsenen Sonderfälle.
Typische Vorteile:
Die Nachteile sind ebenso klar. Recruiting dauert, Ausfallrisiken sind hoch, Schichtmodelle sind teuer und Spezialwissen ist nicht immer verfügbar.
Ein externer Partner ist oft dann sinnvoll, wenn Sie schnell Stabilität brauchen oder Supportzeiten ausweiten wollen, ohne sofort ein volles internes Team aufzubauen.
Outsourcing eignet sich besonders für standardisierbare L1-Prozesse, klar definierte Servicezeiten oder Umgebungen mit schwankender Last. Ein guter Partner bringt Prozesse, Runbooks, Ticketdisziplin und oft auch Erfahrung aus mehreren Kundenumgebungen mit.
Typische Vorteile:
Die Schwächen liegen meist in Übergaben, Wissenserhalt und Integrationsqualität. Ein schlechter Anbieter arbeitet Tickets ab, ohne Ihre Realität wirklich zu verstehen.
Die meisten Unternehmen stellen die falsche Frage. Nicht “Was ist billiger?” ist entscheidend, sondern: Wo entsteht Engpassrisiko?
Wenn Ihr grösstes Risiko Wissensverlust und Sicherheitsnähe ist, spricht viel für intern. Wenn Ihr grösstes Risiko in Lastspitzen, Besetzungsproblemen oder fehlender Supportabdeckung liegt, wird extern schnell attraktiv.
Für CTOs, die den Betrieb rund um Anwendungen mitdenken, ist auch der Übergang zum laufenden Plattform- und Anwendungsbetrieb relevant. In diesem Zusammenhang lohnt ein Blick auf https://www.pandanerds.com/news/application-management-services, weil sich dort gut zeigt, wie Support und laufende technische Betreuung praktisch zusammenhängen.
"Entscheidungshilfe: Wählen Sie nicht das Modell mit dem besten Pitch. Wählen Sie das Modell, das Ihren grössten operativen Engpass am saubersten entschärft."
Sobald das Betriebsmodell feststeht, folgt die Budgetfrage. Viele Teams diskutieren Helpdesk-Kosten zu abstrakt. Sinnvoller ist es, zwischen Kostenlogik und Tool-Stack zu unterscheiden.
Die Kostenlogik beschreibt, wie Sie bezahlen. Der Tool-Stack beschreibt, wofür Sie technisch überhaupt bezahlen.
In der Praxis begegnen Ihnen vor allem drei Modelle.
Pro Agent passt gut, wenn Sie ein klar definiertes internes oder externes Team haben. Die Kosten wachsen dann meist mit der Zahl der Bearbeitenden. Das ist planbar, kann aber unflexibel werden, wenn das Ticketvolumen stark schwankt.
Pro Ticket eignet sich eher bei schwankender Last oder klar umrissenen Supportpaketen. Der Vorteil liegt in der variablen Abrechnung. Der Nachteil: Komplexe Tickets lassen sich schwerer fair bewerten.
Pauschal oder Retainer wird häufig genutzt, wenn feste Servicefenster, definierte Reaktionszeiten und ein kalkulierbares Grundrauschen bestehen. Das Modell ist bequem, birgt aber die Gefahr, dass Leistungsgrenzen unklar bleiben, wenn Scope und Eskalationswege unsauber beschrieben sind.
Eine hilfreiche Faustregel:
Nicht jedes Unternehmen braucht sofort ein grosses ITSM-Paket. Aber fast jedes Team braucht dieselben Grundbausteine.
Der häufigste Fehler ist ein schönes Ticketsystem ohne saubere Prozessanbindung. Dann landet zwar alles in einem Tool, aber niemand weiss, welche Felder Pflicht sind, wann eskaliert wird oder wie Wissen zurück in die Dokumentation fliesst.
Achten Sie bei der Auswahl deshalb auf drei Dinge:
Wer stark im Microsoft-Umfeld arbeitet, sollte die Support-Perspektive rund um Arbeitsplatz, Identitäten und Kollaboration früh mitdenken. Dazu ist https://www.pandanerds.com/news/microsoft-365-beratung als Einordnung hilfreich, weil Helpdesk-Prozesse in vielen KMU direkt an Microsoft-365-Themen hängen.
"Wichtiger Punkt: Das beste Tool ersetzt keine saubere Zuständigkeit. Es verstärkt nur die Qualität Ihres bestehenden Betriebsmodells. Im Guten wie im Schlechten."
Ob Sie einen internen Helpdesk aufbauen oder mit einem Partner arbeiten: Die Auswahl entscheidet weniger über den Start als über die nächsten Monate. Viele Support-Setups scheitern nicht im Pitch, sondern im Onboarding.
Die folgende Checkliste ist bewusst praktisch gehalten. Wenn Sie mehrere Punkte nicht sauber beantworten können, ist das Modell meist noch nicht reif.

Nicht jeder Anbieter oder jedes interne Team passt zu Ihrer Umgebung.
Wenn diese Grundlage fehlt, entsteht kein skalierbarer Betrieb, sondern nur ein neuer Eingangskanal für Chaos.
Gerade bei externem Support bleiben viele Erwartungen zu diffus.
Fragen Sie konkret:
In Deutschland ist das kein Nebenthema. Ein Helpdesk arbeitet oft mit Benutzerkonten, Geräten, Kommunikationsdaten und potenziell sensiblen Inhalten.
Prüfen Sie deshalb mindestens:
Viele CTOs konzentrieren sich zuerst auf Reaktionszeit. Das ist verständlich, aber riskant. Ein schneller Support ohne sauberes Sicherheitsmodell erzeugt später grössere Probleme.
"Praxis-Tipp: Lassen Sie sich nicht nur Funktionen zeigen. Lassen Sie sich zeigen, wie ein reales Ticket unter Ihren Sicherheitsregeln bearbeitet wird."
Die ersten Wochen entscheiden über Akzeptanz im Unternehmen.
Achten Sie auf diese Punkte:
Ein gutes Setup zeigt sich nicht nur in schnell geschlossenen Tickets. Es zeigt sich daran, dass Ihr internes Team wieder planbar arbeiten kann, dass wiederkehrende Störungen sauber dokumentiert werden und dass Nutzer wissen, wohin sie sich wenden müssen.
Wenn nach einigen Wochen immer noch dieselben Menschen per Direktnachricht um Hilfe gebeten werden, wurde kein echter Helpdesk etabliert. Dann haben Sie nur ein weiteres Tool eingeführt.
Die klassische Wahl zwischen komplett intern und komplett extern passt für viele Unternehmen nicht mehr gut. Vor allem KMU und Scale-ups bewegen sich dazwischen.
Sie haben genug Komplexität für professionellen Support, aber oft nicht genug Volumen oder Budget, um jede Ebene vollständig intern zu besetzen. Genau hier entstehen hybride Modelle.
Das Problem ist nicht nur Verfügbarkeit, sondern Wirtschaftlichkeit. 68 Prozent der Unternehmen in Deutschland erwarten 24/7-Support, aber nur 32 Prozent können ihn intern anbieten, unter anderem weil die Personalkosten bei 50 bis 70 Euro pro Stunde liegen. Laut SupportSave können hybride Modelle mit stundenbasierter Abrechnung durch Remote-Spezialisten diese Kosten um bis zu 30 Prozent senken.
Für viele CTOs ist das der praktische Mittelweg. Ein kleines internes Team hält Nähe, Kontext und Steuerung. Externe Spezialisten ergänzen gezielt dort, wo Tiefe oder Abdeckung fehlt.
Ein tragfähiges Modell trennt nicht nach “intern gut, extern billig”, sondern nach Aufgabenlogik.
Ein mögliches Setup:
Hybrid funktioniert oft dort am besten, wo ein Unternehmen bereits ein kleines IT- oder Plattformteam hat, dieses aber nicht jede Supportrolle dauerhaft besetzen kann.
Typische Situationen:
Die Stärke hybrider Modelle liegt nicht nur in den Kosten. Sie liegt darin, dass sie organisatorisch realistischer sind. Sie erlauben Stabilität, ohne dass ein Unternehmen sofort eine volle Supportorganisation aufbauen muss.
Sobald Supportanfragen regelmässig in Chats, E-Mails und Direktnachrichten landen und mehrere Personen ungeplant eingreifen, ist der Punkt meist erreicht. Der Auslöser ist nicht eine feste Unternehmensgrösse, sondern wiederkehrende operative Reibung. Wenn Entwickler oder Admins ständig unterbrochen werden, lohnt sich ein formalisierter Helpdesk fast immer.
Ein Helpdesk löst primär konkrete Störungen und Anfragen. ITSM, also IT Service Management, ist breiter gedacht. Es umfasst auch Prozesse wie Servicekataloge, Änderungsmanagement, Problemmanagement und die systematische Steuerung von IT-Leistungen. Viele Unternehmen starten mit einem Helpdesk und entwickeln daraus später ein reiferes ITSM-Modell.
Standardprobleme wie Passwort-Resets, Zugriffsanfragen, Arbeitsplatzthemen, einfache VPN-Probleme oder bekannte Softwarekonflikte sollten grundsätzlich nicht direkt im Engineering landen. Entwickler sollten nur dort eingebunden werden, wo Produktlogik, Code, Architektur oder tiefere Integrationsfehler tatsächlich betroffen sind. Sonst wird das Produktteam zur allgemeinen Betriebsreserve.
Das hängt stark von Scope, Tooling und vorhandener Dokumentation ab. Schnell starten lässt sich fast immer. Wirklich belastbar wird ein Modell aber erst, wenn Ticketkategorien, Eskalationswege, Wissensdatenbank, Zuständigkeiten und Reporting sauber ineinandergreifen. Entscheidend ist weniger die Erstkonfiguration als die Qualität der ersten Betriebswochen.
Wenn Sie Ihr Team entlasten und technische Kapazität flexibel erweitern möchten, unterstützt PandaNerds Unternehmen in Deutschland mit sorgfältig geprüften Senior-Entwicklern, die sich nahtlos in bestehende Teams integrieren. Das ist besonders dann hilfreich, wenn L2- oder L3-nahe Supportfälle, Plattformthemen oder produktnahe Betriebsaufgaben intern nicht dauerhaft abgedeckt werden können.
































































































.svg)


