.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Ihre App läuft. Kunden nutzen sie. Das Team liefert Features. Und trotzdem kippt die Stimmung irgendwann.
Deployments werden riskanter. Ein kleiner Eingriff bricht an unerwarteter Stelle etwas anderes. Neue Entwickler brauchen zu lange, um sich einzuarbeiten. Support-Tickets häufen sich, obwohl niemand bewusst “schlechten Code” geschrieben hat. Genau an diesem Punkt beginnt für viele Unternehmen die eigentliche Realität der wartung von software.
Für Gründer und neue Engineering-Manager ist das oft irritierend. Die Anwendung ist ja bereits gebaut. Warum frisst sie jetzt so viel Aufmerksamkeit? Die kurze Antwort lautet: Weil Software kein fertiges Objekt ist, sondern ein laufendes System. Sie lebt in einer Umgebung, die sich ständig verändert. Nutzerverhalten ändert sich, Sicherheitsanforderungen ändern sich, Integrationen ändern sich, Geschäftsprozesse ändern sich.
Wer Wartung nur als Reparaturarbeit versteht, reagiert zu spät. Wer Wartung als Managementaufgabe begreift, schützt Geschwindigkeit, Stabilität und Handlungsspielraum.
Viele Teams behandeln Wartung erst dann als Thema, wenn etwas sichtbar kaputtgeht. Das ist verständlich, aber teuer.

Eine Anwendung kann funktional noch “okay” wirken und trotzdem intern bereits in einem schlechten Zustand sein. Typische Anzeichen sind lange Build-Zeiten, schwer verständliche Module, wiederkehrende Produktionsprobleme und eine hohe Abhängigkeit von einzelnen Personen im Team.
Softwarewartung umfasst weit mehr als das Schliessen von Tickets. Sie sichert, dass ein System nutzbar, sicher, erweiterbar und wirtschaftlich betreibbar bleibt.
Dazu gehören unter anderem:
Wer den gesamten Lebenszyklus einer Software betrachtet, merkt schnell: Betrieb und Wartung sind kein Nachtrag, sondern ein eigener Wertschöpfungsbereich.
Technische Schulden entstehen selten spektakulär. Meist wachsen sie in kleinen Entscheidungen. Ein schneller Workaround hier, eine unsaubere Schnittstelle dort, ein ausgelassenes Refactoring wegen Zeitdruck.
"Praxisbeobachtung: Die teuersten Wartungsprobleme sind oft nicht die grössten Bugs, sondern die vielen kleinen Stellen, an denen niemand mehr sicher ändern möchte."
Für ein Unternehmen hat das direkte Folgen. Produktideen dauern länger. Onboarding wird mühsamer. Roadmaps verlieren Verlässlichkeit. Wartung ist deshalb kein Kostenblock ohne Rendite, sondern eine Voraussetzung dafür, dass das Produkt überhaupt weiterentwickelt werden kann.
Eine gute Wartungsstrategie schützt also nicht nur die Verfügbarkeit. Sie schützt auch Ihre Lieferfähigkeit.
In der Praxis hilft eine einfache Unterscheidung. Nicht jede Wartungsaufgabe verfolgt dasselbe Ziel. Wenn Teams alle Arbeiten nur als “Bugfixes” verbuchen, fehlt die Grundlage für Priorisierung, Kapazitätsplanung und sinnvolle SLAs.
Ein hilfreiches Bild ist die Autowartung. Ein platter Reifen, ein Motorumbau, ein Tuning und ein regelmässiger Ölwechsel sind alles Wartung. Aber die Auslöser und Ziele sind unterschiedlich.
Laut FIDA bilden korrigierende, präventive, perfektionierende und adaptive Softwarewartung den Kern einer standardisierten Strategie. Standardisierte Prozesse, die alle vier Typen abdecken, können Ausfälle um bis zu 60 % senken. Proaktive Planung kann die Lebensdauer einer Software um 2 bis 3 Jahre verlängern, und optimierte Prozesse können die MTTR auf unter 4 Stunden reduzieren. Ungewartete Software verursacht in Deutschland Schäden in Milliardenhöhe. Diese Angaben finden sich im Beitrag zur Software-Wartung bei FIDA.
Das ist der klassische Fall. Etwas funktioniert nicht wie vorgesehen, also behebt das Team den Fehler.
Beim Auto wäre das der platte Reifen nach einer Panne. In Software kann das vieles sein: ein Login-Fehler nach einem Browser-Update, eine falsche Preisberechnung im Checkout oder ein API-Timeout, das Bestellungen blockiert.
Korrigierende Wartung ist notwendig, aber sie sollte nicht den gesamten Kalender auffressen. Wenn ein Team fast nur noch reaktiv arbeitet, fehlt Zeit für Stabilisierung und Verbesserung.
Typische Aufgaben:
Hier bleibt die Software nicht wegen eines internen Fehlers stehen, sondern weil sich die Umgebung ändert.
Beim Auto entspräche das einem Umbau für einen neuen Kraftstoff oder geänderte Vorschriften. Bei Software sind die Treiber oft Betriebssysteme, Cloud-Dienste, Browser, App-Store-Regeln, neue Compliance-Vorgaben oder geänderte Schnittstellen externer Partner.
Adaptive Wartung wird oft unterschätzt, weil das Produkt “doch eigentlich läuft”. Aber sobald ein Zahlungsanbieter seine API verändert oder ein mobiles Betriebssystem neue Berechtigungen verlangt, muss das System angepasst werden.
Beispiele:
Dieser Typ verbessert ein System, obwohl es bereits funktioniert. Das Ziel ist nicht Reparatur, sondern bessere Qualität.
Beim Auto wäre das Motortuning oder die Optimierung des Verbrauchs. In Software geht es um Performance, Benutzerfreundlichkeit, Wartbarkeit und Stabilität.
Perfektionierende Wartung lohnt sich besonders dort, wo Teams regelmässig an denselben Modulen arbeiten. Eine sauberere Architektur, klarere Tests oder eine bessere Query-Strategie sparen später Zeit bei jeder weiteren Änderung.
Dazu zählen etwa:
"Wenn ein Team ein Modul jedes Quartal anfasst, ist jede Verbesserung an dieser Stelle mehrfach wertvoll."
Präventive Wartung passiert, bevor ein sichtbares Problem auftritt. Sie reduziert die Wahrscheinlichkeit, dass Fehler, Sicherheitslücken oder Ausfälle überhaupt entstehen.
Beim Auto ist das der Ölwechsel. Niemand wartet damit, bis der Motor blockiert. In der Softwarewelt entspricht das Dependency-Updates, Log-Analyse, Monitoring, Sicherheitsprüfungen, Backups und gezieltem Refactoring von riskanten Bereichen.
Viele Manager tun sich mit präventiver Wartung schwer, weil der Erfolg unsichtbar ist. Man sieht keinen dramatischen Vorher-Nachher-Effekt. Dafür sinkt das operative Risiko.
Typische präventive Aufgaben:
Ein klassischer Fehler ist falsche Zuordnung. Ein Dependency-Update wird als “technische Spielerei” abgetan, obwohl es adaptive oder präventive Wartung sein kann. Ein Refactoring wird verschoben, obwohl es eigentlich perfektionierende Wartung mit direktem Geschäftsnutzen ist.
Hilfreich sind drei einfache Fragen:
Wer diese Typen sauber trennt, plant realistischer. Vor allem aber erkennt das Management besser, warum Wartung nicht nur aus “Bugfixing” besteht.
Ein guter Wartungsprozess macht aus einem diffusen Problem eine steuerbare Aufgabe. Ohne klaren Ablauf verlieren Teams Zeit in Rückfragen, doppelter Analyse und unklarer Verantwortung.
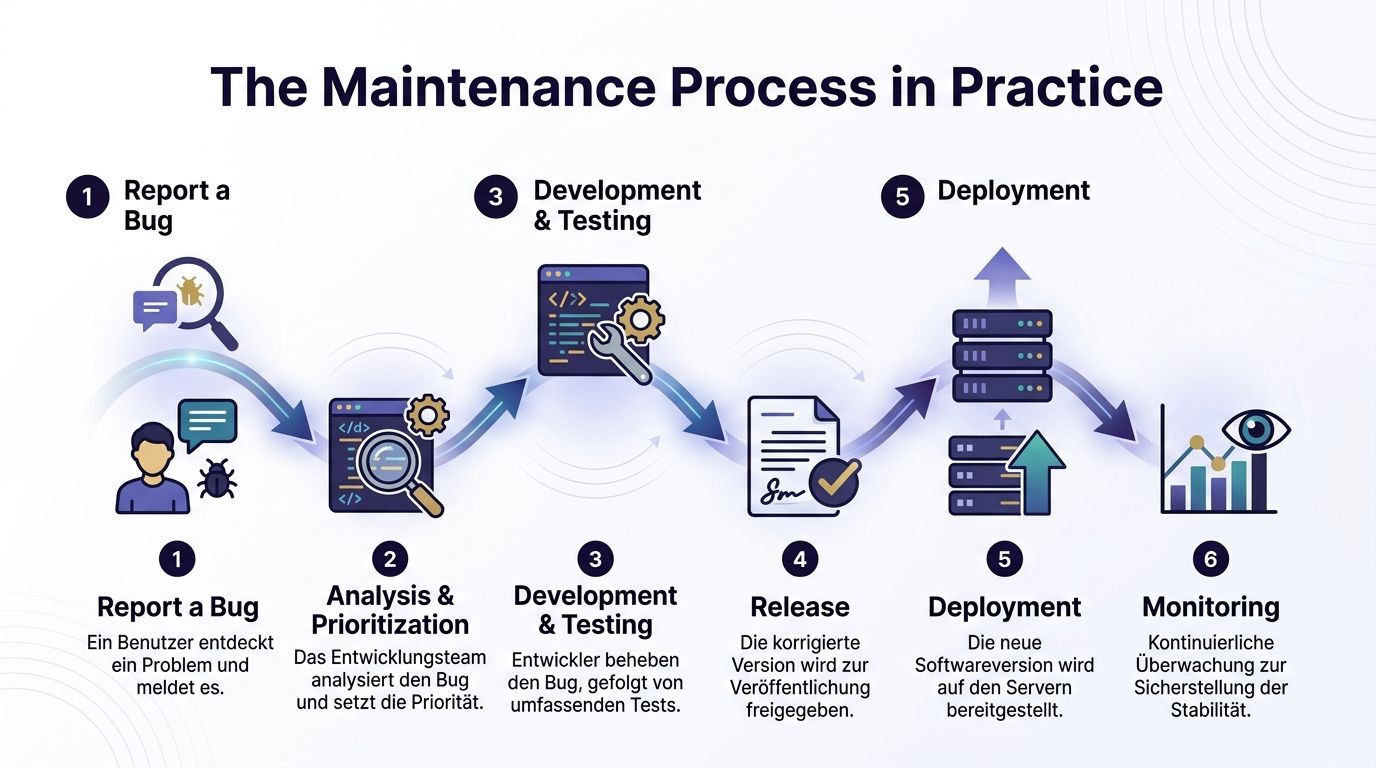
In vielen Unternehmen beginnt eine Wartungsaufgabe unspektakulär. Ein Nutzer meldet einen Fehler. Der Vertrieb bemerkt ein Problem in einem Demo-Flow. Monitoring schlägt an. Entscheidend ist nicht der Startpunkt, sondern wie sauber das Team danach arbeitet.
Ein praxistauglicher Ablauf besteht aus wenigen klaren Stationen:
"Ein guter Wartungsprozess endet nicht mit dem Merge, sondern erst dann, wenn das System in Produktion stabil läuft."
Viele Reibungsverluste entstehen nicht im Code, sondern an Schnittstellen zwischen Rollen.
L1-Support oder Servicedesk nimmt Meldungen auf, filtert Dubletten und sammelt die ersten Fakten. Diese Rolle schützt Entwickler davor, rohe und unklare Anfragen direkt bearbeiten zu müssen.
Product Owner oder Engineering Manager priorisiert nach Geschäftsauswirkung. Ein Darstellungsfehler im Adminbereich ist etwas anderes als ein Fehler im Zahlungsfluss.
Entwickler übernehmen Analyse und Umsetzung. Bei kritischen oder diffusen Problemen sollte früh ein erfahrener Entwickler eingebunden werden, weil Root-Cause-Analyse in komplexen Systemen selten linear verläuft.
QA prüft, ob die Korrektur belastbar ist. Gerade in gewachsenen Produkten spart eine saubere Verifikation viel spätere Nacharbeit.
DevOps oder Platform-Team unterstützt bei Deployment, Observability und Rollback-Strategien, wenn Änderungen im Betrieb abgesichert werden müssen.
Hier hilft das Pareto-Prinzip. In der Softwarewartung konzentrieren sich etwa 80 Prozent der Änderungen auf rund 20 Prozent des Codes, wie eine empirische Untersuchung in deutschen Unternehmen zeigt. Die Management-Folge ist klar: Wer diese änderungsintensiven Bereiche identifiziert, kann Ressourcen gezielt priorisieren und Kosten besser steuern. Das wird in der Langfassung zur Softwarewartung bei der GI beschrieben.
Für die Praxis bedeutet das:
Nicht jedes Modul verdient denselben Wartungsaufwand. Ein erfahrener Tech Lead behandelt die kritischen 20 Prozent anders als den ruhigen Rest.
Drei Probleme tauchen fast überall auf:
Wenn Sie diese Engpässe beseitigen, wird Wartung planbarer. Nicht perfekt. Aber beherrschbar.
Wartungskosten wirken oft unberechenbar, weil Unternehmen sie falsch strukturieren. Das Problem ist selten nur die Höhe des Budgets. Häufig passt das Modell nicht zur tatsächlichen Art der Arbeit.
Wer die wartung von software plant, sollte zwei Dinge trennen: das Kostenmodell und das Serviceversprechen. Das eine regelt, wie bezahlt wird. Das andere regelt, was im Ernstfall passieren muss.
Es gibt kein universell richtiges Modell. Es gibt nur passende und unpassende Modelle.
Fixed Price passt für eng umrissene Aufgaben, etwa ein definiertes Upgrade oder einen bekannten Sanierungsblock. Sobald sich der Umfang unterwegs verschiebt, wird das Modell mühsam.
Time and Material eignet sich besser für reale Wartungsarbeit. Tickets, Incidents und technische Altlasten verhalten sich selten planbar. Sie brauchen hier Transparenz bei Aufwand, Priorisierung und Freigabe.
Dedizierte Teams sind sinnvoll, wenn ein System dauerhaft Aufmerksamkeit braucht. Der grosse Vorteil ist Kontinuität. Das Team kennt Architektur, Stolperstellen und Betriebsrealität bereits.
Ein SLA ist kein juristischer Schmuck. Es ist ein Betriebsinstrument.
Diese Punkte sollten enthalten sein:
Ein brauchbares SLA unterscheidet nach Geschäftswirkung, nicht nach Lautstärke im Chat.
Ein einfaches Raster:
"Faustregel: Formulieren Sie Prioritäten so, dass auch Nicht-Techniker sie einordnen können. “Zahlungen nicht möglich” ist besser als “Severity 1”."
Reaktive Arbeit wirkt im Moment oft billiger. Sie ist es meist nicht.
Laut den angegebenen Branchenbenchmarks können proaktive Wartungsstrategien die Betriebskosten um 20 bis 30 % senken, die Systemverfügbarkeit auf über 99 % steigern und ungeplante Stillstandszeiten um bis zu 50 % reduzieren. Für SMEs ist das besonders relevant, weil ungewartete Systeme in Deutschland zu bis zu 40 % höheren Ausfallkosten führen können. Diese Angaben finden sich auf der Seite zu Maintenance und Modernisierung von SaM Solutions.
Das heisst nicht, dass jedes Team ein grosses Wartungsprogramm braucht. Aber jedes Team braucht einen klaren Mindeststandard:
Wer Wartung nur einkauft, wenn es brennt, bezahlt fast immer doppelt. Erst im Incident. Dann nochmals in der nachträglichen Stabilisierung.
Manuelle Wartung skaliert schlecht. Sobald ein Produkt wächst, reichen Slack-Nachrichten und Bauchgefühl nicht mehr aus.
Die Basis bildet eine saubere Toolchain. Monitoring mit Prometheus, Grafana oder Zabbix zeigt, wenn Systeme abweichen. Error-Tracking mit Sentry macht Anwendungsfehler sichtbar. Zentrale Logs in ELK oder Datadog helfen bei der Ursachenanalyse. CI/CD mit GitLab CI, Jenkins oder GitHub Actions sorgt dafür, dass Fixes reproduzierbar getestet und ausgerollt werden.
Automatisierung spart nicht nur Zeit. Sie reduziert Streuverluste.
Einige Beispiele aus der Praxis:
Der oft übersehene Hebel liegt bei KI-gestützter Wartung für KMU. Laut den im Haufe-Beitrag zusammengefassten Angaben stufen 68 % der deutschen KMU Wartungskosten als unvorhersehbar ein, während nur 22 % KI-Tools nutzen. Gleichzeitig erhöht der EU AI Act laut derselben Zusammenfassung die Anforderungen an Transparenz, worauf 75 % der KMU unvorbereitet seien. Flexible Modelle mit externen Senior-Entwicklern können Wartungsprozesse dabei um bis zu 40 % kosteneffizienter gestalten. Diese Angaben stehen im Beitrag über den unterschätzten Faktor Software- und IT-Wartung bei Haufe.
Der praktische Nutzen von KI liegt nicht in Magie, sondern in Entlastung bei wiederkehrender Arbeit:
Wichtig ist die Reihenfolge. Erst Prozesse stabilisieren, dann KI daraufsetzen. Schlechte Eingangsdaten und chaotische Abläufe werden durch KI nicht automatisch gut.
Sie brauchen kein riesiges Budget, um professioneller zu werden.
Starten Sie mit drei Bausteinen:
Wenn Sie CI-Strukturen nachschärfen möchten, hilft auch ein Blick auf was Continuous Integration in der Praxis leistet.
Eine mögliche Ergänzung ist ein flexibles Resourcing-Modell mit externen Senior-Entwicklern, etwa über PandaNerds, wenn intern zwar Produktwissen vorhanden ist, aber Kapazität für Stabilisierung, Modernisierung oder komplexe Wartungsaufgaben fehlt.
"Gute Automatisierung ersetzt keine Verantwortung. Sie gibt dem Team mehr Zeit für die Aufgaben, die Erfahrung und Urteilskraft brauchen."
Die Übergabe der Wartung an ein externes Team scheitert selten am Willen. Sie scheitert an fehlendem Kontext.

Wenn Wissen nur in Köpfen steckt, startet jeder externe Partner zu langsam. Gute Übergaben machen Systeme nicht nur verständlich, sondern handhabbar.
Viele Teams dokumentieren entweder zu wenig oder das Falsche. Ein seitenlanges Wiki ersetzt keine brauchbaren Betriebsinformationen.
Wirklich nützlich sind:
Ein Dokument allein beantwortet selten die entscheidenden Fragen. Besser funktionieren gemeinsame Sessions.
Sinnvolle Formate sind:
"Geben Sie nicht nur den Code ab. Geben Sie den Entscheidungskontext mit."
Externe Wartung funktioniert am besten, wenn sie wie integrierte Zusammenarbeit organisiert wird. Nicht wie ein Ticket-Briefkasten.
Dazu gehören klare Ansprechpartner, ein gemeinsames Backlog, feste Sync-Termine und eindeutige Eskalationspfade. Wer dafür ein strukturiertes Betriebsmodell sucht, findet im Überblick zu Application Management Services eine gute Orientierung für Rollen und Verantwortlichkeiten.
Eine gute Übergabe nimmt nicht Kontrolle weg. Sie macht Kontrolle überhaupt erst belastbar, weil Wissen, Prozesse und Erwartungen explizit werden.
Wartung wird gern als Aufgabe betrachtet, die man an die jüngsten Teammitglieder delegiert. Das klingt effizient, ist aber oft ein Denkfehler.
Komplexe Wartung verlangt Urteilsvermögen. Ein Senior-Entwickler sieht schneller, ob ein Fehler lokal ist oder auf ein Architekturproblem hinweist. Er behebt nicht nur das sichtbare Symptom, sondern prüft, warum es überhaupt auftreten konnte.
Ein Junior kann oft einen konkreten Defekt sauber fixen. Das ist wertvoll. Aber bei gewachsenen Systemen reicht das nicht immer.
Senior-Entwickler bringen vor allem in drei Situationen überproportionalen Nutzen:
Der eigentliche Vorteil liegt nicht nur in schnellerer Arbeit. Er liegt in besseren Entscheidungen.
Ein erfahrener Entwickler stellt andere Fragen:
Diese Perspektive senkt Risiko. Vor allem bei Wartung ist das wichtiger als reine Umsetzungsgeschwindigkeit.
Für Gründer und Tech Leads heisst das praktisch: Seniorität ist in der Wartung keine Komfortoption. Sie ist oft die günstigere Entscheidung über die Zeit.
Wenn ein erfahrener Entwickler ein Problem an der Wurzel löst, sinken Rückläufer, Regressionen und Folgearbeit. Das macht Release-Zyklen verlässlicher und schafft Freiraum für echte Produktentwicklung.
Gerade in Phasen mit wenig interner Kapazität oder hoher Unsicherheit lohnt es sich deshalb, Wartung nicht als Restaufgabe zu behandeln, sondern gezielt mit erfahrenen Leuten zu besetzen.
Software altert nicht wie Hardware, aber sie verkompliziert sich. Jede neue Anforderung, jede Integration und jede schnelle Entscheidung hinterlässt Spuren. Deshalb ist wartung von software keine Nebenaufgabe des Betriebs, sondern ein zentraler Teil der Produktstrategie.
Wer die vier Wartungstypen sauber unterscheidet, Aufgaben mit klaren Prozessen abwickelt, Kostenmodelle und SLAs passend wählt und in sinnvolle Automatisierung investiert, gewinnt mehr als technische Ordnung. Das Unternehmen gewinnt Tempo, Verlässlichkeit und Entscheidungsfreiheit.
Für Gründer, CTOs und neue Manager lohnt sich ein nüchterner Blick auf den aktuellen Zustand:
"Nachhaltige Software entsteht nicht durch einen grossen Rewrite. Sie entsteht durch konsequente, gut organisierte Wartung."
Wenn Sie die Wartung Ihrer Anwendung strukturierter aufstellen oder gezielt durch erfahrene Entwickler ergänzen möchten, lohnt sich ein Blick auf PandaNerds. Dort können Unternehmen Senior-Entwickler flexibel in bestehende Teams integrieren, um Wartung, Stabilisierung und Weiterentwicklung mit klaren Prozessen und ohne langfristigen Overhead abzudecken.
































































































.svg)


