.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Viele CTOs stehen an einem ähnlichen Punkt. Die Anwendung läuft, das Team liefert, aber das bisherige Hosting bremst plötzlich an Stellen, die vorher niemanden gestört haben. Deployments dauern zu lang, Lastspitzen werden riskant, Security-Reviews ziehen sich, und bei jeder Wachstumsentscheidung hängt die Infrastruktur mit am Tisch.
Web hosting in aws ist dann nicht nur ein Umzug zu einem anderen Provider. Es ist eine Architekturentscheidung. Sie beeinflusst, wie schnell Teams releasen, wie sauber Compliance umgesetzt wird, wie belastbar die Plattform unter Last bleibt und wie gut sich Kosten steuern lassen.
Für deutsche Unternehmen kommt noch eine weitere Ebene dazu. Regionale Datenspeicherung, Betriebsstabilität in Europa, sinnvolle Trennung von Verantwortlichkeiten und ein Setup, das nicht nur für den MVP funktioniert, sondern auch für das nächste Produktstadium.
Wer AWS nur als Sammlung einzelner Cloud-Services betrachtet, bewertet die Plattform zu klein. Für anspruchsvolle Webprojekte ist AWS vor allem ein Betriebsmodell. Es erlaubt, Infrastruktur, Sicherheit, Ausfallschutz und Automatisierung auf einer gemeinsamen Basis aufzubauen, statt diese Themen nachträglich an klassisches Hosting anzuflanschen.
Für deutsche Unternehmen ist die Frankfurt-Region eu-central-1 oft der entscheidende Einstiegspunkt. AWS betreibt diese Region seit 2014, sie ist für DSGVO-konforme Datenspeicherung optimiert, und in Europa erreicht AWS einen PUE-Wert von bis zu 1,04, verglichen mit 1,63 für On-Premises. Das macht die Plattform nicht nur regulatorisch relevant, sondern auch interessant für Unternehmen, die Nachhaltigkeit ernsthaft in ihre Infrastrukturentscheidungen einbeziehen wollen (AWS-Statistiken zur Frankfurt-Region und Energieeffizienz).
Viele Projekte starten auf Shared Hosting, Managed WordPress oder einer einzelnen VM. Das ist für Prototypen oft ausreichend. Die Probleme beginnen, wenn mehrere Anforderungen gleichzeitig entstehen:
Klassische Hosting-Modelle können einzelne Punkte davon gut abdecken. Sie tun sich aber schwer, wenn alles zusammenkommt. Genau dort spielt AWS seine Stärke aus. Die Plattform ist nicht deshalb interessant, weil jeder Service maximal komplex wäre, sondern weil sich Dienste konsistent kombinieren lassen.
AWS ist dann sinnvoll, wenn sich die Anwendung voraussichtlich verändert. Vielleicht beginnt das Produkt als monolithische Webanwendung. Später kommen API-Services, asynchrone Jobs, getrennte Frontends, interne Tools oder regionale Anforderungen dazu. Wer auf AWS sauber startet, muss diese Entwicklung nicht bei jeder Stufe mit einem kompletten Plattformwechsel bezahlen.
Dazu kommt die operative Seite. Teams können Verantwortung sauber schneiden:
Für viele CTOs ist eu-central-1 nicht nur ein Punkt auf der Karte. Die Region vereinfacht Gespräche mit Datenschutz, Legal und Enterprise-Kunden. Wenn Datenhaltung, Backups und Laufzeitumgebungen bewusst in der EU geplant werden, reduziert das Reibung in Ausschreibungen und Security-Fragebögen spürbar.
"Praxisgedanke: Infrastrukturentscheidungen sollten nicht nur auf den heutigen Traffic optimiert werden. Wichtiger ist, ob das Setup in zwölf Monaten noch tragfähig ist, wenn Team, Produkt und Risiko zunehmen."
AWS ist deshalb für anspruchsvolle Projekte selten die billigste Antwort auf die erste Hosting-Frage. Es ist oft die belastbarste Antwort auf die zweite und dritte. Nämlich dann, wenn aus einer Website ein Produkt wird und aus einem Produkt eine Plattform.
Montagmorgen, 8:30 Uhr. Das Produktteam will schneller releasen, der Vertrieb braucht verlässliche Antwortzeiten für Demos, und Security fragt nach klaren Verantwortlichkeiten für Secrets, Netzwerkgrenzen und Deployments. In diesem Moment geht es bei der Architekturwahl nicht um den modernsten Stack, sondern um ein Betriebsmodell, das zu Anwendung, Team und Wachstumsphase passt.
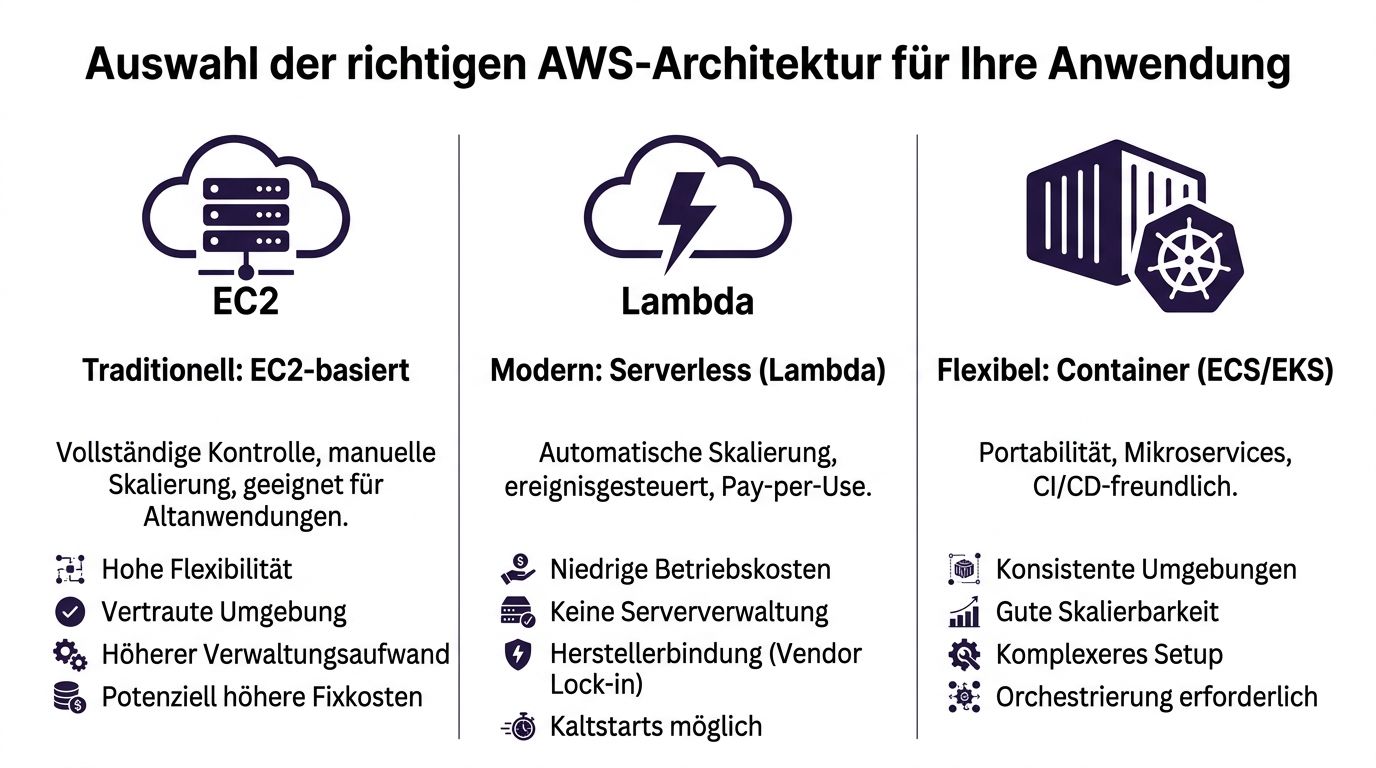
Für CTOs sind drei Muster relevant: statisch, dynamisch und containerisiert. Die technische Umsetzung ist nur ein Teil der Entscheidung. Mindestens genauso wichtig sind Release-Frequenz, Betriebsaufwand, Sicherheitsmodell, CI/CD-Reife und die Frage, ob das Team die gewählte Architektur auch unter Last und im Incident sauber betreiben kann.
Für Marketingseiten, Dokumentationsportale, Headless-Frontends oder klar getrennte Frontends mit API-Backend ist ein statisches Setup oft die wirtschaftlichste AWS-Option. S3 und CloudFront reduzieren die Zahl der beweglichen Teile deutlich. Keine dauerhaft laufenden Webserver, kein OS-Patching, weniger Angriffsfläche auf der Compute-Ebene.
Typische Kandidaten sind:
Der Vorteil liegt nicht nur in den Kosten, sondern in der operativen Klarheit. Deployments werden zu Artefakt-Veröffentlichungen. Rollbacks sind einfacher. Das Zusammenspiel mit CI/CD ist sauber, wenn Builds versioniert, Cache-Invalidierungen kontrolliert und Umgebungen klar getrennt werden.
Die Grenze dieses Modells ist ebenso klar. Sobald Rendering, Sessions, Nutzerzustand oder serverseitige Integrationen geschäftskritisch werden, reicht ein rein statisches Setup nicht mehr aus. Dann entstehen schnell Zusatzkonstruktionen, die auf dem Architekturdiagramm einfach aussehen, operativ aber unübersichtlich werden.
"Gut geeignet: Wenn das Frontend schnell auslieferbar sein soll, Releases häufig sind und serverseitige Logik bewusst aus dem Web-Layer herausgehalten wird."
Für gewachsene Webanwendungen bleibt EC2 hinter einem Application Load Balancer ein vernünftiges Muster. Das gilt besonders für Shop-Systeme, klassische CMS-Landschaften, interne Portale und Anwendungen, bei denen Laufzeitverhalten, Pakete, Dateisystem oder Hintergrundprozesse eng mit dem Produkt verbunden sind.
Dieses Modell ist oft der beste Kompromiss, wenn ein Team mehr Kontrolle braucht, aber keine Plattform für Container aufbauen will. Es passt auch dann, wenn eine Modernisierung schrittweise erfolgen muss und ein Monolith vorerst wirtschaftlicher ist als eine komplette Zerlegung in Services.
Dynamisches Hosting ist meist die richtige Wahl, wenn:
Der Preis für diese Kontrolle ist Betriebsaufwand. Patch-Management, Härtung, Zertifikate, Health Checks, Rollback-Pfade und Kapazitätsplanung müssen aktiv gepflegt werden. Viele Teams unterschätzen dabei nicht die Erstimplementierung, sondern den Regelbetrieb nach sechs Monaten. Wer EC2 wählt, sollte deshalb früh festlegen, wie Images gebaut, Deployments automatisiert, Logs zentralisiert und Sicherheitsupdates in den Release-Prozess eingebettet werden.
Container sind sinnvoll, wenn nicht mehr eine Anwendung im Fokus steht, sondern ein wachsender Satz von Services. ECS ist für viele Teams der pragmatischere Einstieg in AWS als ein sofortiger Wechsel auf Kubernetes. Fargate kann den Betriebsaufwand weiter senken, wenn das Team Containerstandards braucht, aber keine eigenen Hosts verwalten will.
Container lohnen sich besonders in diesen Fällen:
Der strategische Vorteil liegt in der Standardisierung. Build, Test und Deployment lassen sich sauberer durchziehen. Umgebungsunterschiede nehmen ab. Sicherheits- und Compliance-Vorgaben können über Images, Task-Definitionen, Rollen und Pipeline-Gates besser durchgesetzt werden.
Die Kehrseite ist reale Komplexität. Netzwerkdesign, Observability, Secret Management, Service-Kommunikation und Rechtekonzepte müssen bewusst modelliert werden. Container beseitigen keinen Betriebsaufwand. Sie verschieben ihn von Serverpflege zu Plattformdisziplin.
Wer die Denkweise hinter solchen Modellen einordnen will, findet im PandaNerds-Beitrag zu cloud-nativ einfach erklärt eine gute Grundlage.
Die häufigste Fehlentscheidung ist nicht technische Inkompetenz, sondern ein falscher Zeithorizont. Frühe Teams bauen zu viel Plattform für zu wenig Produkt. Spätere Teams halten zu lange an einer simplen VM-Struktur fest, obwohl Release-Risiko, Teamgröße und Verfügbarkeitsanforderungen längst ein anderes Modell verlangen.
Eine einfache Heuristik funktioniert in vielen Fällen gut:
Ich rate CTOs in der Regel zu einer Architektur, die einen klaren nächsten Schritt erlaubt. Ein statisches Frontend mit getrenntem API-Layer lässt sich später gut erweitern. Ein sauber geschnittener Monolith auf EC2 kann schrittweise in Container überführt werden. Problematisch sind vor allem Setups, die schon am Anfang maximale Flexibilität versprechen, aber niemand im Team effizient betreiben kann.
Die beste Architektur ist die, die Ihre Organisation mit vertretbarem Aufwand sicher deployen, überwachen und weiterentwickeln kann.
Freitag, 18:40 Uhr. Ein Release ist live, der Traffic steigt unerwartet, und in einer Availability Zone kippt eine Instanz nach der anderen aus dem Pool. Für den CTO ist in diesem Moment nicht entscheidend, ob AWS theoretisch alle Bausteine für Hochverfügbarkeit bietet. Entscheidend ist, ob Architektur, Deployment-Pfad und Betriebsmodell so gewählt wurden, dass ein Teilfehler kein Kundenproblem wird.
Genau dort trennt sich ein Setup, das nur skaliert, von einem Setup, das verlässlich liefert. Hochverfügbarkeit entsteht in AWS aus klaren Abhängigkeiten, sauberen Fehlergrenzen und einer Architektur, die das Team auch unter Zeitdruck beherrscht.
Der sinnvolle Startpunkt ist eine VPC über mindestens zwei Availability Zones, mit einer Trennung der Rollen pro Subnetz. Öffentliche Subnetze gehören dem Application Load Balancer. Applikations-Workloads laufen in privaten Subnetzen. Datenbanken und andere zustandsbehaftete Komponenten bekommen eigene private Segmente mit eng gefassten Regeln.
Das klingt nach Standard. In der Praxis entscheidet genau diese Trennung darüber, ob ein Routing-Fehler lokal bleibt oder ob er Web-Tier, Backend und Datenbank gleichzeitig trifft.
Für viele produktive Webanwendungen funktioniert dieses Muster gut:
Wer Lastwachstum realistisch einplant, sollte die Architektur nicht nur auf Verfügbarkeit, sondern auch auf Skalierungspfad prüfen. Eine gute Einordnung dazu liefert dieser Beitrag zur strategischen Skalierung von Software-Systemen.
Ein Application Load Balancer verteilt nicht einfach nur Traffic. Er entscheidet mit darüber, wann Instanzen oder Tasks aus dem Verkehr gezogen werden, wie TLS terminiert wird und ob Routing-Regeln bei Teilfehlern noch sauber greifen.
Die häufigsten Probleme liegen nicht im fehlenden Load Balancer, sondern in seiner Konfiguration. Health Checks sind oft zu oberflächlich, Cooldown-Zeiten zu knapp und Zielgruppen falsch geschnitten. Dann reagiert die Plattform zwar sichtbar, aber nicht hilfreich. Sie skaliert in einen Fehler hinein oder hält kranke Knoten zu lange im Pool.
Ich empfehle für geschäftskritische Anwendungen drei Prüfungen vor dem Go-live:
Gerade bei containerisierten Setups wird dieser Punkt unterschätzt. Die Infrastruktur startet schnell. Die Anwendung ist trotzdem noch nicht bereit, wenn Caches leer sind, Migrationen laufen oder abhängige Dienste hinterherhinken.
Viele Teams investieren zuerst in das Web-Tier, weil sich dort Skalierung am sichtbarsten anfühlt. Die eigentliche Verfügbarkeitsgrenze liegt aber oft bei der Datenbank.
Für relationale Workloads ist ein Multi-AZ-Setup bei Amazon RDS in produktiven Umgebungen meist die vernünftige Basis. AWS beschreibt Failover-Verhalten und Architekturprinzipien für hochverfügbare Datenbank-Deployments in der Amazon RDS Multi-AZ Dokumentation. Für interne Backoffice-Tools kann Single-AZ genügen. Für kundennahe Anwendungen mit Umsatzbezug ist es oft die falsche Stelle zum Sparen.
Dasselbe gilt für Dateispeicher. Lokale Uploads auf mehreren Applikationsinstanzen erzeugen früher oder später Inkonsistenzen. Objekt-Storage in S3 oder ein bewusst gewählter Shared-Storage-Ansatz verhindert, dass eine horizontale Skalierung neue Fehlerklassen einführt.
Eine einfache Regel hilft hier: Compute darf austauschbar sein. Daten dürfen es nicht ungeplant sein.
Ein hochverfügbares Setup ist nicht nur gegen Ausfälle geschützt, sondern auch gegen vermeidbare Angriffsflächen. Security Groups gehören deshalb zur Architekturarbeit, nicht in die Restekiste des Go-live.
Offene Management-Ports, breit erlaubter Ost-West-Verkehr und gemeinsam genutzte Regeln für mehrere Schichten rächen sich schnell. Häufig kommt der Ausfall dann nicht durch AWS, sondern durch eine spätere Änderung, die niemand mehr sauber abgrenzen kann. Sicherheitsforscher von Trend Micro beschreiben in ihrem Bericht zu cloud security misconfigurations, wie Fehlkonfigurationen in Netz- und Zugriffsregeln zu den häufigsten Ursachen für Cloud-Risiken gehören.
Vor öffentlich erreichbaren Anwendungen gehört ein AWS WAF an den Einstiegspunkt. AWS dokumentiert Funktionen, Regeltypen und den praktischen Einsatz im AWS WAF Developer Guide. Für CTOs ist weniger die Existenz des Dienstes interessant als die Betriebsfrage: Wer pflegt Regeln, wertet False Positives aus und verbindet WAF-Ereignisse mit Incident-Prozessen?
Der operative Mindeststandard ist klar:
Bei EC2-basierten Workloads scheitert Sicherheit oft nicht an fehlenden Tools, sondern an ungeklärter Verantwortung. Wer Updates strukturiert organisieren will, findet im Leitfaden zu effizientes Patch Management eine brauchbare Ergänzung für den Betriebsprozess.
Ein Setup ist erst dann belastbar, wenn Releases unter normalen Bedingungen und im Fehlerfall reproduzierbar bleiben. Manuelle Deployments, SSH-Hotfixes und nicht versionierte Infrastruktur zerstören diese Eigenschaft schnell.
Für ein skalierendes Team reicht meist ein pragmatisches Modell: Build in einer Pipeline, Artefakte versionieren, Deployments automatisieren, Rollback technisch vorbereiten. Ob dahinter EC2, ECS oder ein anderer Laufzeitansatz steht, ist zweitrangig. Der wichtige Punkt ist, dass Änderungen kontrolliert, wiederholbar und beobachtbar ausgerollt werden.
Blue-Green- oder Rolling-Deployments sind keine akademische Kür. Sie senken das Risiko geplanter Änderungen. Gerade bei Monolithen auf EC2 ist das oft der schnellste Weg zu mehr Stabilität, ohne sofort die gesamte Plattform zu ersetzen.
Nicht jedes Team braucht ein ausgefeiltes Plattformmodell. Fast jedes Team braucht aber klare Untergrenzen für Betrieb und Wiederherstellung.
Die eigentliche Reife zeigt sich nicht am Architekturdiagramm. Sie zeigt sich daran, wie kontrolliert ein Team auf Lastspitzen, fehlerhafte Releases und Teilstörungen reagiert. Genau das macht aus AWS-Hosting eine tragfähige Betriebsplattform statt nur eine Sammlung guter Einzelservices.
Ein typisches AWS-Problem zeigt sich nicht beim ersten Go-live, sondern beim dritten Release unter Zeitdruck. Das Team will eine kleine Änderung ausrollen, ein Hotfix muss in die Produktion, und plötzlich hängt alles an manuellen Schritten, uneinheitlichen Umgebungen und fehlender Transparenz im Deployment. Genau an diesem Punkt entscheidet sich, ob AWS nur Infrastruktur bereitstellt oder eine belastbare Delivery-Plattform ist.
Für CTOs ist die Kernfrage deshalb nicht, welches Tool in der Pipeline läuft. Die Kernfrage lautet: Wie zuverlässig bringt das Team Änderungen in Produktion, ohne Verfügbarkeit, Sicherheit und Kostenkontrolle zu verlieren?
CI/CD beginnt mit klaren Artefakten, festen Qualitätsgrenzen und einem Deployment-Pfad, der für alle Umgebungen gleich funktioniert. Wer Build, Test und Release noch zwischen Konsole, Shell-Skripten und Einzelwissen verteilt, skaliert weder Geschwindigkeit noch Betriebssicherheit. Eine saubere Einführung von Continuous Integration im Softwareteam schafft hier die Grundlage, weil Änderungen früher validiert, Konflikte schneller sichtbar und Releases planbarer werden.
Infrastructure as Code gehört in diesem Modell nicht in die Kategorie "später aufräumen". Terraform, AWS CDK oder CloudFormation sorgen dafür, dass VPCs, Load Balancer, IAM-Rollen, ECS-Services oder Datenbankparameter versioniert, reviewbar und reproduzierbar bleiben. Das ist für skalierende Teams wichtiger als die konkrete Toolwahl. Ohne IaC entstehen Konfigurationsabweichungen zwischen Staging und Production, und genau dort beginnen viele schwer erklärbare Ausfälle.
Die sinnvolle Deployment-Strategie hängt vom Hosting-Modell ab:
Gerade bei EC2-basierten Setups wird operative Exzellenz oft unterschätzt. Viele Teams automatisieren das Applikationsdeployment, lassen aber die Pflege der Basis-Images, Paketstände und Sicherheitsupdates halb manuell laufen. Das erhöht den Betriebsaufwand und öffnet vermeidbare Lücken. Für gewachsene Umgebungen mit mehreren Instanzen und klaren Wartungsfenstern ist ein effizientes Patch Management oft wirtschaftlicher als selbstgebaute Routinen, die im Alltag nicht konsequent eingehalten werden.
Ein belastbarer Minimalstandard für den Betrieb umfasst mehr als eine grüne Pipeline:
Der häufigste Fehler liegt nicht in fehlenden AWS-Services. Er liegt in fehlender Betriebsdisziplin. Ein Team führt ECS ein, aber ohne klare Resource Limits. Es nutzt Terraform, aber ohne Review-Prozess. Es baut eine Pipeline, die deployed, aber keine Freigabelogik für produktive Änderungen kennt. Dann wirkt die Plattform modern, der Betrieb bleibt jedoch fragil.
Operative Exzellenz entsteht, wenn Delivery, Security und Plattformentscheidungen zusammengeführt werden. CTOs sollten deshalb früh festlegen, wer Deployments freigibt, wie Drift erkannt wird, welche Änderungen auditierbar sein müssen und welche Recovery-Ziele technisch nachgewiesen werden müssen. Erst dann trägt AWS Hosting nicht nur Last, sondern auch Organisationswachstum.
Web hosting in aws ist für CTOs kein Infrastrukturdetail. Es ist ein Hebel für Liefergeschwindigkeit, Stabilität, Security und Kostenkontrolle. Die Qualität einer AWS-Umgebung zeigt sich nicht daran, wie viele Services verbaut wurden, sondern wie gut Architektur und Teamstruktur zueinander passen.
Statisches Hosting mit S3 und CloudFront ist stark, wenn Einfachheit und Performance im Vordergrund stehen. Dynamische Setups mit EC2, ALB und RDS sind oft der richtige Weg für geschäftskritische Anwendungen mit gewachsener Logik. Container auf ECS oder Fargate lohnen sich, wenn Teams mehrere Services konsistent ausrollen und betreiben müssen.
Die strategische Frage lautet deshalb nicht nur: Können wir das auf AWS hosten? Sondern: Welches Modell macht uns in zwölf oder vierundzwanzig Monaten schneller und sicherer?
Gut geplante AWS-Architekturen schaffen Spielraum. Für häufigere Releases, klarere Sicherheitsgrenzen, bessere Ausfallsicherheit und kontrollierbares Wachstum. Genau darin liegt der Wettbewerbsvorteil.
Wenn Sie für anspruchsvolle AWS-Architekturen erfahrene Unterstützung brauchen, kann PandaNerds Ihr Team mit sorgfältig ausgewählten Senior-Entwicklern verstärken. Besonders für Scale-ups, KMUs und Produktteams, die Infrastruktur, Delivery und Betrieb parallel professionalisieren müssen, ist ein eingespielter zusätzlicher Senior-Level-Arm oft der schnellste Weg zu einer tragfähigen Umsetzung.
































































































.svg)


