.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Ein typisches Muster in wachsenden Produktteams sieht so aus: Das Produkt gewinnt Nutzer, die Plattform wird relevanter, und plötzlich landet jede zweite Störung direkt bei den Entwicklern. Ein Login-Fehler, ein langsamer Report, eine Integration, die nur bei einem bestimmten Kunden ausfällt. Nichts davon wirkt gross genug für ein echtes Incident-Team. Aber in Summe zerlegt es den Arbeitstag.
Für Gründer und neue Engineering Manager ist das ein heikler Punkt. Wenn Senior Engineers ständig aus geplanter Arbeit herausgerissen werden, leidet nicht nur die Liefergeschwindigkeit. Auch Architekturentscheidungen, Code-Qualität und technisches Lernen im Team werden schlechter, weil alle nur noch auf Sicht fahren.
Genau an dieser Stelle wird level 2 support interessant. Nicht als klassische Helpdesk-Schicht, sondern als operative und technische Pufferzone zwischen Standard-Support und tiefer Produktentwicklung. Gut aufgesetzt schützt diese Ebene Fokuszeit, beschleunigt Diagnose und sorgt dafür, dass Probleme nicht nur geschlossen, sondern verstanden werden.
Viele Teams bauen Support anfangs informell auf. Das ist nachvollziehbar. Die ersten Kunden melden Probleme direkt im Slack-Channel, ein Entwickler prüft schnell die Logs, jemand aus dem Produktteam beantwortet Rückfragen, und irgendwie läuft es.
Dann wächst das Unternehmen. Aus einzelnen Ausnahmen wird Routine. Ein Backend-Entwickler schaut morgens kurz in ein Ticket und verliert danach den halben Tag mit Reproduktion, Datenprüfung und Rückfragen an Customer Success. Nachmittags bleibt die eigentliche Feature-Arbeit liegen. Das Problem ist nicht nur die Menge der Anfragen. Das Problem ist der ständige Kontextwechsel.
Ein Team ohne saubere Support-Stufen hat meist drei Symptome:
Level 2 support entlastet genau diese Engstelle. Er übernimmt Fälle, die für Skripte und Standardantworten zu komplex sind, aber noch keine tiefgreifende Produktänderung im Kernsystem brauchen. Das ist in SaaS-Teams oft der Bereich zwischen „Ticket weiterleiten“ und „Engineering muss eine neue Lösung bauen“.
Probleme verschwinden nicht, nur weil man sie schnell beantwortet. Sie verschwinden erst, wenn jemand die Ursache sauber untersucht.
In frühen Phasen ist jede Stunde eines erfahrenen Entwicklers teuer. Nicht nur finanziell, sondern strategisch. Diese Leute sollen Systeme widerstandsfähiger machen, technische Risiken reduzieren und schwierige Produktentscheidungen tragen. Wenn sie stattdessen einen grossen Teil ihrer Zeit mit wiederkehrenden Support-Diagnosen verbringen, verliert das Unternehmen Hebelwirkung.
Ein gut organisierter Level-2-Bereich schafft deshalb mehr als Entlastung. Er stabilisiert das operative System des Teams. Level 1 fängt Standardfälle ab. Level 2 untersucht, priorisiert und löst komplexere bekannte Störungen. Erst wenn das Problem tiefer in Architektur, Produktlogik oder neue Implementierung hineinreicht, geht es an Level 3.
Für Gründer ist das die relevante Perspektive: Level 2 support ist kein Zusatzaufwand, sondern eine Schutzschicht für Fokus, Qualität und Skalierbarkeit.
Wenn Support-Stufen unscharf bleiben, landet am Ende alles bei den gleichen Leuten. Deshalb lohnt sich eine klare Abgrenzung. Die einfachste Analogie ist ein Krankenhaus.
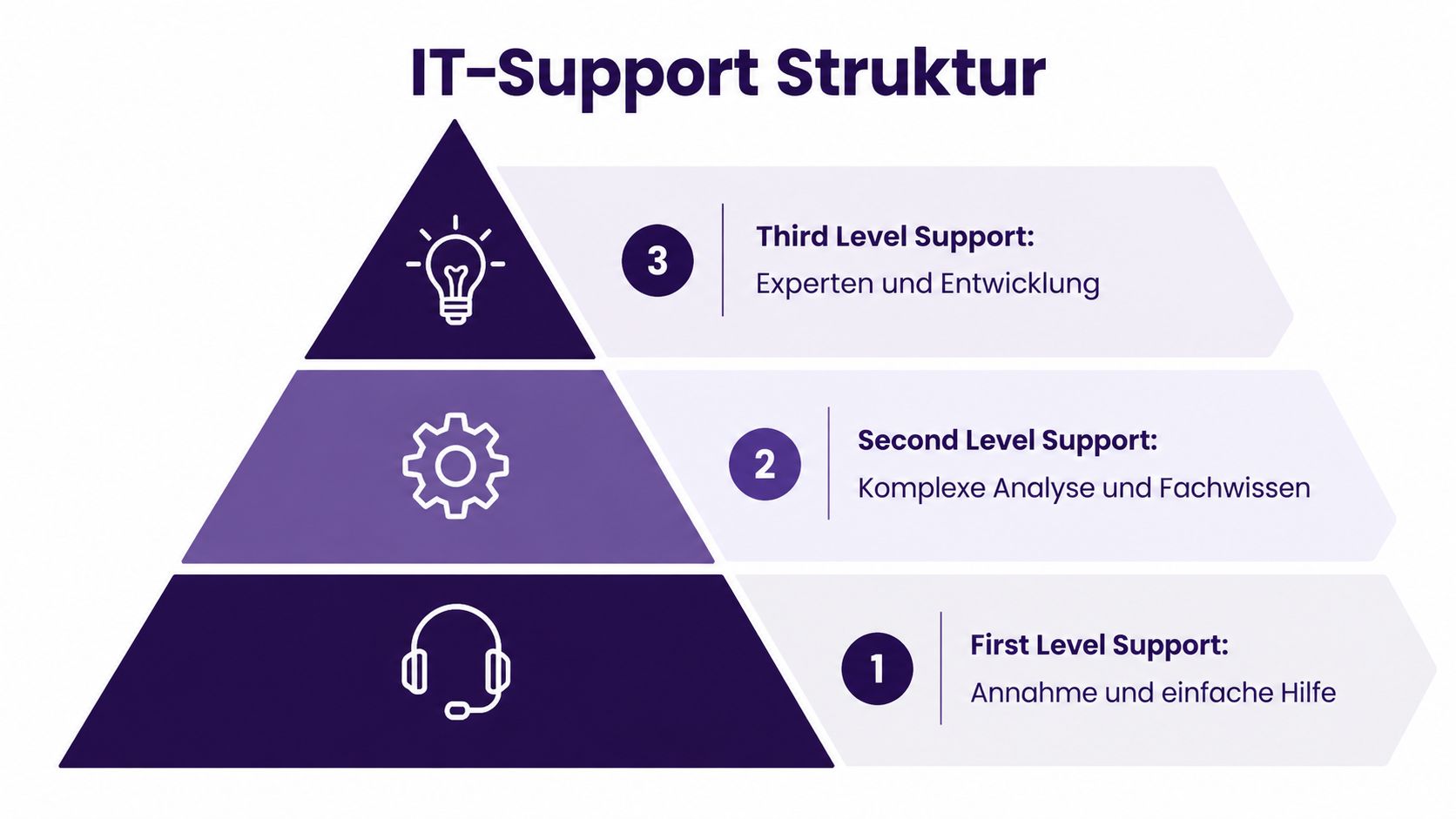
Level 1 ist die Triage. Dort wird aufgenommen, vorsortiert und alles behandelt, was klar beschrieben und standardisiert lösbar ist. Passwörter, Standardkonfigurationen, bekannte Bedienfehler, einfache Rückfragen. Wer das genauer einordnen will, findet bei First Level Support im Überblick eine gute Ausgangsbasis.
Level 2 ist der Facharzt. Hier reicht ein Skript nicht mehr. Die Person muss Symptome einordnen, Zusammenhänge erkennen und technische Ursachen prüfen. Das Problem ist komplexer, aber grundsätzlich innerhalb bekannter Systemgrenzen lösbar.
Level 3 ist der Chirurg. Diese Ebene greift ein, wenn neue Lösungen entwickelt werden müssen, tiefe Änderungen an Code, Architektur oder Infrastruktur nötig sind oder ein Fehler nur durch Eingriffe im Kernsystem behoben werden kann.
Die Trennlinie zwischen Level 1 und Level 2 ist nicht „schwierigeres Ticket“. Sie liegt bei Zugriff, Diagnosefähigkeit und Systemverständnis.
Laut dieser Einordnung zu Support-Tiers verfügen Level-2-Techniker über erhöhte Systemzugriffsrechte und spezialisierte Diagnosewerkzeuge. Im Unterschied zu Level 1, das vordefinierte Skripte befolgt, verlangt Level-2-Arbeit kritisches Denken und ein tiefes Verständnis der Systemarchitektur. Dort wird auch beschrieben, dass Level-2-Techniker typischerweise 2-4 Stunden pro Ticket aufwenden.
Das passt gut zur Realität moderner Produktteams. Ein L2-Fall ist oft kein „ich weiss die Antwort nicht“, sondern eher:
Viele Teams machen einen Fehler und definieren L2 zu breit. Dann wird daraus ein Auffangbecken für alles, was unangenehm ist. Das funktioniert nicht.
Level 2 ist nicht:
Praxisregel: Wenn ein Ticket nur durch Änderung der Produktlogik oder durch einen neuen Entwicklungszyklus lösbar ist, verlässt es den Level-2-Bereich.
Für Gründer und Engineering Manager ist die wichtigste Einsicht simpel: L2 ist die Ebene, in der bekannte Systeme mit nicht-trivialen Mitteln untersucht und stabilisiert werden. Nicht mehr Frontline. Noch nicht Kernentwicklung.
Im Alltag besteht level 2 support aus sauberer Diagnosearbeit. Das klingt unspektakulär, ist aber operativ oft der Unterschied zwischen hektischem Feuerlöschen und kontrollierter Problemlösung.

Nehmen wir einen häufigen Fall in einem SaaS-Team. Ein Kunde meldet, dass ein Report plötzlich unvollständig ist. Level 1 prüft erst die offensichtlichen Dinge: Benutzerrolle, bekannte Einschränkungen, Standardfehlerbilder. Nichts passt. Das Ticket geht an L2.
Dann beginnt die eigentliche Arbeit:
Die Rolle ist breiter als in klassischen Helpdesks. In agilen Teams gehören oft diese Tätigkeiten dazu:
Wer ähnliche operative Verantwortlichkeiten im Infrastrukturumfeld einordnen möchte, findet bei typischen Aufgaben eines Systemadministrators nützliche Parallelen.
Ein häufiger Denkfehler lautet: L2 löst Tickets, L1 kommuniziert, Entwicklung baut Features. In der Praxis fehlt dann der wichtigste Hebel, nämlich Wissensaufbau.
Laut dieser Beschreibung der Support-Level gehört es zu den kritischen Aufgaben im Level-2-Support, Dokumentation zu erstellen oder zu aktualisieren, damit Level-1-Teams ähnliche Probleme künftig selbstständig lösen können. Diese Praxis reduziert wiederkehrende Probleme und verbessert zukünftige Lösungszeiten messbar.
Das heisst konkret:
Gute L2-Arbeit endet nicht mit „Issue resolved“. Sie endet mit „Beim nächsten Mal kann das Team schneller und sicherer reagieren“.
Ohne klare Prozesse wird level 2 support schnell zum Warteraum. Tickets stapeln sich, niemand weiss genau, wann eskaliert werden soll, und jede Seite hat eine andere Erwartung an Reaktionszeit und Verantwortung.

Gerade in deutschen KMU und Scale-ups fehlt oft die saubere Definition dieser Übergänge. Laut dieser Analyse zu Level-2-Support berichten 67% der mittelständischen Unternehmen über unklare Eskalationsprozesse. Gleichzeitig fordern 73% der deutschen IT-Manager eine bessere Dokumentation von Level-2-Kriterien.
Das überrascht nicht. Viele Teams definieren nur, wer Tickets annimmt. Nicht aber, wann ein Ticket von L1 zu L2 wechselt, welche Informationen mitgeliefert werden müssen und wann L2 die Entwicklung einbeziehen darf.
Sie brauchen keine riesige Metrik-Landschaft. Einige wenige Kennzahlen reichen, wenn sie sauber erhoben und gemeinsam verstanden werden.
Diese Kennzahlen sollten nicht isoliert betrachtet werden. Wenn etwa die Eskalationsrate sinkt, aber die Reopen Rate steigt, hat das Team Probleme wahrscheinlich nur tiefer im System versteckt.
Messen Sie nicht nur Geschwindigkeit. Messen Sie, ob das Team Probleme dauerhaft aus dem System entfernt.
Ein sinnvolles SLA beschreibt nicht nur Zeitfenster. Es beschreibt Erwartungen. Für Startups und Produktteams ist oft wichtiger, wann eine qualifizierte Analyse beginnt, als ein künstlich kurzes Antwortversprechen.
Die Eskalation von L1 nach L2 sollte an konkrete Fragen gebunden sein:
Wenn mehrere dieser Fragen mit Ja beantwortet werden, ist L2 meist richtig.
Für Teams, die ihre Arbeitsweise breiter schärfen wollen, ist der Blick auf Methoden hilfreich, mit denen sich agile Prozesse optimieren lassen. Viele Support-Probleme sind am Ende keine Tool-Probleme, sondern Übergabe- und Priorisierungsprobleme.
Ein schlanker Ablauf funktioniert oft besser als ein detailverliebtes Regelwerk:
Wenn Sie das einführen, gewinnt das Team vor allem eines: weniger Grauzonen.
Die Frage ist selten, ob Sie level 2 support brauchen. Die eigentliche Frage lautet, wer ihn übernehmen soll.

In der Praxis sehe ich meist drei Aufbaumuster:
Für klassische IT-Umgebungen kann ein separates Support-Team sinnvoll sein. In Startups und Scale-ups ist die Lage anders. Dort hängen Supportfälle oft direkt an Produktlogik, Release-Zyklen, Integrationen und Datenmodellen. Ein rein ausgelagerter Standard-Support stösst schnell an Grenzen, weil Kontext fehlt.
Ein externer Senior-Entwickler, der in den Delivery-Prozess eingebunden ist, bringt einen Vorteil, den klassische Support-Strukturen selten haben: Er versteht nicht nur das Symptom, sondern das System dahinter.
Das verändert die Qualität von L2-Arbeit deutlich:
Wer das organisatorisch abwägen möchte, findet bei Outsourcing von Dienstleistungen im Überblick hilfreiche Entscheidungsdimensionen.
Es gibt keinen Idealfall für alle. Diese Leitfragen helfen meist weiter:
Intern passt besser, wenn Sie bereits ein stabiles Produkt, konstante Supportlast und genug erfahrene Leute für eine dedizierte Rolle haben.
Extern oder hybrid passt besser, wenn Ihr Team klein ist, die Problemtypen stark variieren oder Ihr Produkt tiefes technisches Verständnis verlangt, ohne dass Sie sofort zusätzliche Vollzeitstellen schaffen wollen.
Der Fehler liegt oft nicht im Outsourcing selbst. Der Fehler liegt darin, Support ohne Produktkontext auszulagern.
Für junge Firmen ist deshalb ein hybrides Modell häufig am vernünftigsten. Ein kleiner interner Kern behält Priorisierung und Nutzerkontext. Eingebundene Senior-Entwickler übernehmen L2-Diagnosen, dokumentieren Muster und entlasten das Kernteam dort, wo technische Tiefe wirklich zählt.
Nicht „mehr Tools“, sondern die richtigen Kategorien. Ohne diese Basis arbeitet L2 blind:
Weniger wichtig ist die Tool-Marke. Entscheidend ist, dass Ticket, Monitoring und Dokumentation zusammenpassen.
Ja, aber nur mit klaren Regeln. In kleinen Unternehmen ist das sogar normal. Problematisch wird es erst, wenn dieselbe Person gleichzeitig Incident-Firefighter, Feature-Entwickler und Architekturverantwortlicher ist.
Drei Schutzmechanismen helfen:
Wenn diese Regeln fehlen, kippt das Modell schnell. Dann wirkt es effizient, ist aber in Wahrheit nur personengebundene Improvisation.
Ja, vor allem beim Diagnosekontext.
Bei SaaS kontrolliert Ihr Team die Plattform stärker. L2 arbeitet oft mit zentralem Monitoring, Release-Kontext, Feature-Flags, Tenant-spezifischen Daten und Integrationen. Die Herausforderung liegt meist in Skalierung, Nebenwirkungen von Änderungen und verteilten Systemen.
Bei On-Premise ist die Umgebung heterogener. Dort spielen Kundeninfrastruktur, Netzwerke, lokale Konfigurationen, Berechtigungsmodelle und Versionunterschiede eine grössere Rolle. L2 braucht deshalb oft mehr Routine in Umgebungsanalyse und sauberer Eingrenzung.
Das Grundprinzip bleibt gleich: L2 untersucht technische Probleme innerhalb bestehender Systeme. Aber die Art der Unsicherheit ist unterschiedlich. In SaaS fragen Sie häufiger: „Was ist in unserem System passiert?“ Bei On-Premise eher: „Ist das Produkt betroffen oder die konkrete Kundenumgebung?“
Gute L2-Teams formulieren am Ende jeder Analyse eine klare Antwort auf drei Punkte: Was ist passiert, wie sicher ist diese Einschätzung, und was verhindert den nächsten ähnlichen Fall.
Wenn Sie Level-2-Support nicht als isolierte Supportfunktion, sondern als technischen Bestandteil Ihres Delivery-Systems aufbauen wollen, lohnt sich ein Blick auf PandaNerds. Dort finden Unternehmen erfahrene Senior-Entwickler, die sich in bestehende Teams integrieren, operative Last abfangen und gleichzeitig technisches Wissen im Team verankern.
































































































.svg)


