.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Sie merken, dass etwas langsam ist. Nutzer warten auf Antworten, das Team diskutiert über Datenbank-Indizes, jemand will einen Cache einbauen, jemand anderes vermutet das Frontend. Nach zwei Wochen wurde viel geändert, aber niemand kann sauber sagen, was tatsächlich besser geworden ist.
Genau dort scheitert Performance-Optimierung oft. Nicht an fehlenden Tools, sondern an fehlender Disziplin. Performance Optimierung ist kein Sammeln kleiner Tricks. Sie ist ein Entscheidungsprozess unter technischen und wirtschaftlichen Randbedingungen. Wer ohne Messung optimiert, produziert leicht Aktivität statt Wirkung.
In der Praxis zählt deshalb weniger, wer den cleversten Micro-Optimierungstrick kennt. Entscheidend ist, ob ein Team Engpässe reproduzierbar identifiziert, Änderungen isoliert testet und Verbesserungen an Nutzerwirkung und Geschäftslogik koppelt.
Die erste Regel ist einfach: Nicht optimieren, bevor Sie gemessen haben. Informatik Aktuell betont genau diesen Punkt und empfiehlt, Antworten nicht nur im Durchschnitt, sondern nach Median und 95%-Perzentil auszuwerten, um langsame Use Cases und schlechte Worst-Case-Performance sichtbar zu machen (Informatik Aktuell zur messbasierten Performance-Optimierung).
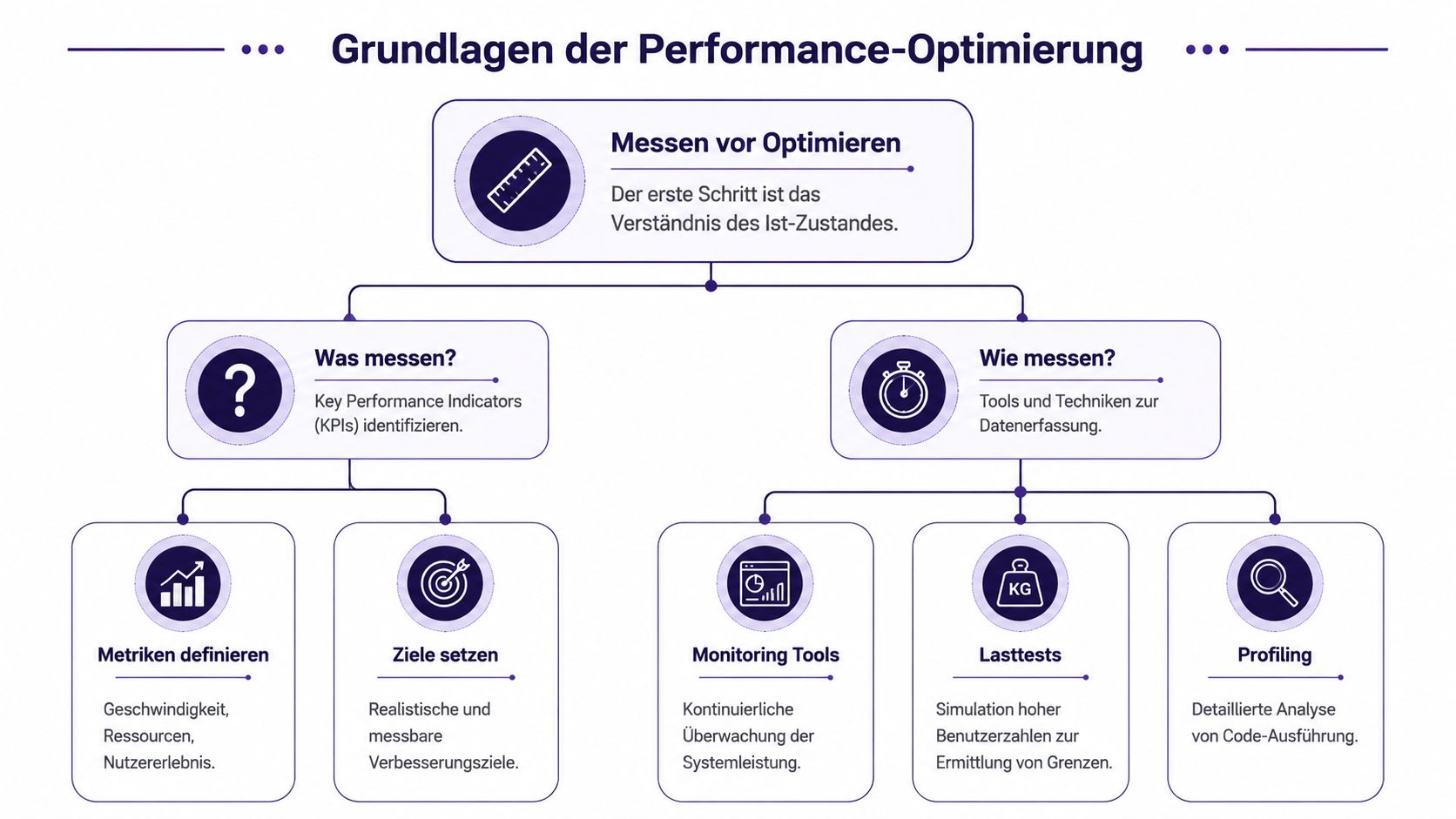
Der Durchschnitt lügt oft. Ein System kann im Mittel schnell wirken und trotzdem für einen relevanten Teil der Nutzer spürbar träge sein. Wenn Sie nur auf Mittelwerte schauen, übersehen Sie genau die Fälle, die Support-Tickets, Abbrüche und Frust erzeugen.
Nicht jedes Produkt braucht dieselben Kennzahlen. Ein internes Backoffice-System hat andere Prioritäten als ein E-Commerce-Frontend oder eine API für mobile Clients. Trotzdem gibt es einige Metrik-Gruppen, die fast immer sinnvoll sind:
"Praktische Regel: Definieren Sie Metriken immer entlang von Nutzerpfaden, nicht entlang von Teamgrenzen. Nutzer erleben kein „Backend“ oder „Frontend“. Sie erleben Wartezeit."
Ein gutes Dashboard beantwortet drei Fragen in wenigen Sekunden: Was ist langsam, für wen ist es langsam, und seit wann ist es langsam? Wenn eines davon fehlt, ist das Dashboard eher Dekoration als Steuerungsinstrument.
Viele Teams instrumentieren alles und gewinnen trotzdem kaum Klarheit. Besser ist ein kleines, belastbares Set.
Messen Sie ausserdem immer in einer Form, die Vergleiche zulässt. Wenn sich Lastprofil, Datenbasis und Umgebung bei jedem Test ändern, können Sie Ergebnisse kaum bewerten. Wer intern Leistungsdaten im Team oder in Ressourcenpools strukturiert beobachten will, findet auch ausserhalb des klassischen Engineering-Kontexts im Beitrag zu Performance-Tracking im Mitarbeiterpool einen nützlichen Blick auf Messdisziplin und Vergleichbarkeit.
Für die operative Ableitung lohnt sich ein sauberer KPI-Rahmen. Ein praxisnaher Einstieg dazu ist dieser Beitrag von PandaNerds zu KPI und Business Intelligence.
Sobald klar ist, dass ein System langsam ist, beginnt die eigentliche Arbeit. Nicht jede hohe Latenz ist ein Codeproblem. Manchmal liegt die Zeit in Datenbankzugriffen, manchmal in Serialisierung, manchmal im Netzwerk, manchmal in unnötigen UI-Re-Renders. Profiling dient dazu, Vermutungen durch Belege zu ersetzen.

Methodisch belastbare Performance-Optimierung folgt einem klaren Ablauf: erst messen, dann analysieren, dann gezielt ändern und anschliessend über Monitoring stabilisieren. Fachquellen raten zudem, nur eine Änderung pro Iteration zu testen, damit Ursache und Wirkung nicht verschwimmen (ZEP zur methodischen Prozessoptimierung).
In der Praxis hat sich ein einfacher Ablauf bewährt:
Viele Engineers sehen eine Flame Graph und springen sofort auf die oberste langsame Methode. Das ist oft zu grob. Eine breite Funktion ist nur dann relevant, wenn sie im problematischen Szenario auch wirklich dominant ist.
Fragen Sie bei der Analyse immer:
"Eine langsame Funktion ist nicht automatisch das Problem. Sie ist oft nur der Ort, an dem sich ein Architekturfehler bemerkbar macht."
Lokal lassen sich CPU- und Memory-Profiler sehr aggressiv einsetzen. In Produktion braucht es vorsichtigere Techniken. Sampling statt invasiver Instrumentierung, kurze Diagnosefenster statt Dauerprofiling, und immer eine Rückfalloption.
Ein häufiger Fehler: Teams analysieren nur lokal mit kleinen Testdaten und ziehen daraus Produktionsschlüsse. Das funktioniert selten. Wenn ein Request erst mit realer Datenmenge oder unter konkurrierender Last kippt, hilft Ihnen die schönste lokale Profilsession nur begrenzt.
Deshalb ist die beste Analyse oft eine Kombination: reproduzierbarer Lastfall, produktionsnahe Testumgebung, leichtgewichtiges Tracing in Produktion und gezielte Detailmessung in einer kontrollierten Umgebung.
Viele der teuersten Performance-Probleme entstehen nicht im offensichtlichen Hotspot, sondern in unscheinbaren Wiederholungen. Ein Endpoint lädt zu viele Felder. Ein Service ruft dieselbe Information mehrfach ab. Eine Liste mit hundert Einträgen triggert hundert Detailabfragen. Die Anwendung funktioniert korrekt, aber sie arbeitet gegen sich selbst.
Für Datenbank- und API-Optimierung sind in der Praxis vor allem Datenreduktion, Batch- oder Bulk-Operationen und Caching relevant. Der Grundsatz ist klar: Nur abfragen, was tatsächlich benötigt wird, und selten ändernde Daten nicht wiederholt laden (Datacenter-Insider zur softwarebezogenen Performance-Optimierung).
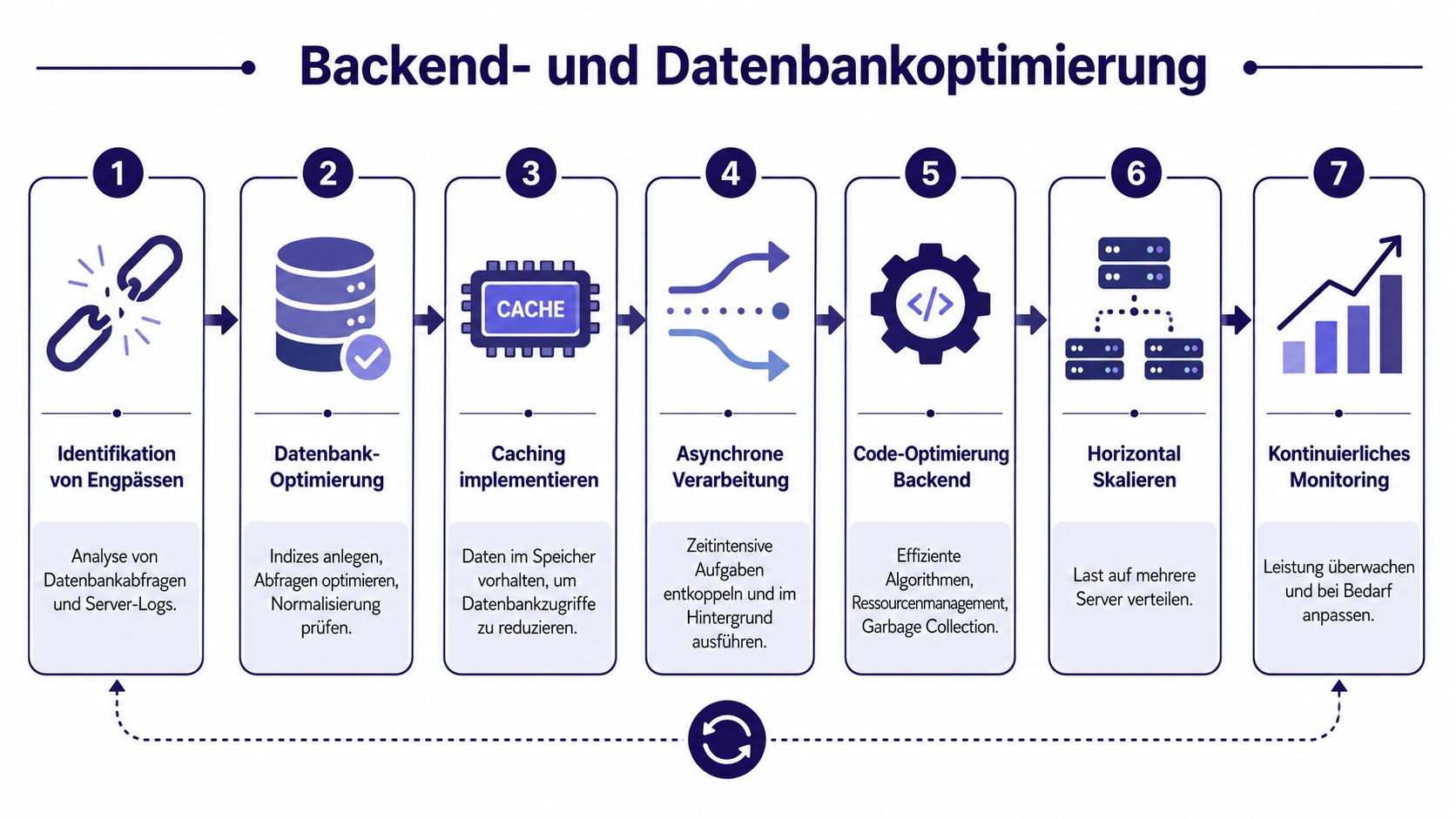
Ein typisches Beispiel aus dem Alltag: Eine API liefert Bestellungen mit Kundendaten. Die erste Abfrage holt die Bestellungen. Danach lädt das System für jede Bestellung separat den zugehörigen Kunden. Das fällt bei wenigen Datensätzen kaum auf. Unter Last explodieren Antwortzeit und Datenbanklast.
Die Lösung ist nicht immer „mehr Hardware“. Oft reicht eine der folgenden Massnahmen:
Caching reduziert Last, aber es erhöht Komplexität. Der Nutzen ist hoch, wenn Daten selten ändern und oft gelesen werden. Der Schaden ist hoch, wenn Teams unklar lassen, wann Daten ungültig werden oder welche Konsistenz erwartet wird.
Eine einfache Entscheidungslogik:
Wenn Sie Caching einführen, definieren Sie vorher drei Dinge: Quelle der Wahrheit, Invalidierungslogik und tolerierbare Staleness. Ohne diese Klärung wird Cache schnell zur Fehlerquelle.
Auch scheinbar fachliche API-Entscheidungen sind Performance-Entscheidungen. Eine zu chatty API zwingt Clients zu vielen Roundtrips. Eine zu generische API liefert zu viel Payload. Ein ungeklärtes Schema für Expand-Felder oder Filter führt oft zu übergrossen Responses oder ineffizienten DB-Zugriffen.
Hilfreich sind in der Praxis vor allem:
"Backend-Performance verbessert sich selten durch einen einzelnen Trick. Meist entsteht der Gewinn aus weniger Daten, weniger Roundtrips und weniger Wiederholung."
Ein Backend kann sauber optimiert sein und sich für Nutzer trotzdem träge anfühlen. Das passiert, wenn das Frontend zu viel JavaScript lädt, Render-Pfade blockiert oder Interaktionen erst spät sichtbar werden. Nutzer bewerten nicht Ihre Architektur. Sie bewerten, ob die Oberfläche sofort reagiert.
Aktuelle Analysen zeigen, dass viele Teams zwar Symptome wie langsame Time-to-First-Feedback oder FPS-Einbrüche im Frontend messen, aber die eigentliche Ursachenhierarchie nicht sauber auflösen. Genau deshalb ist eine systematische Priorisierung wichtiger als eine lange Liste einzelner Tuning-Ideen (Digital Engineering Magazin zu Performance Engineering und Priorisierung).
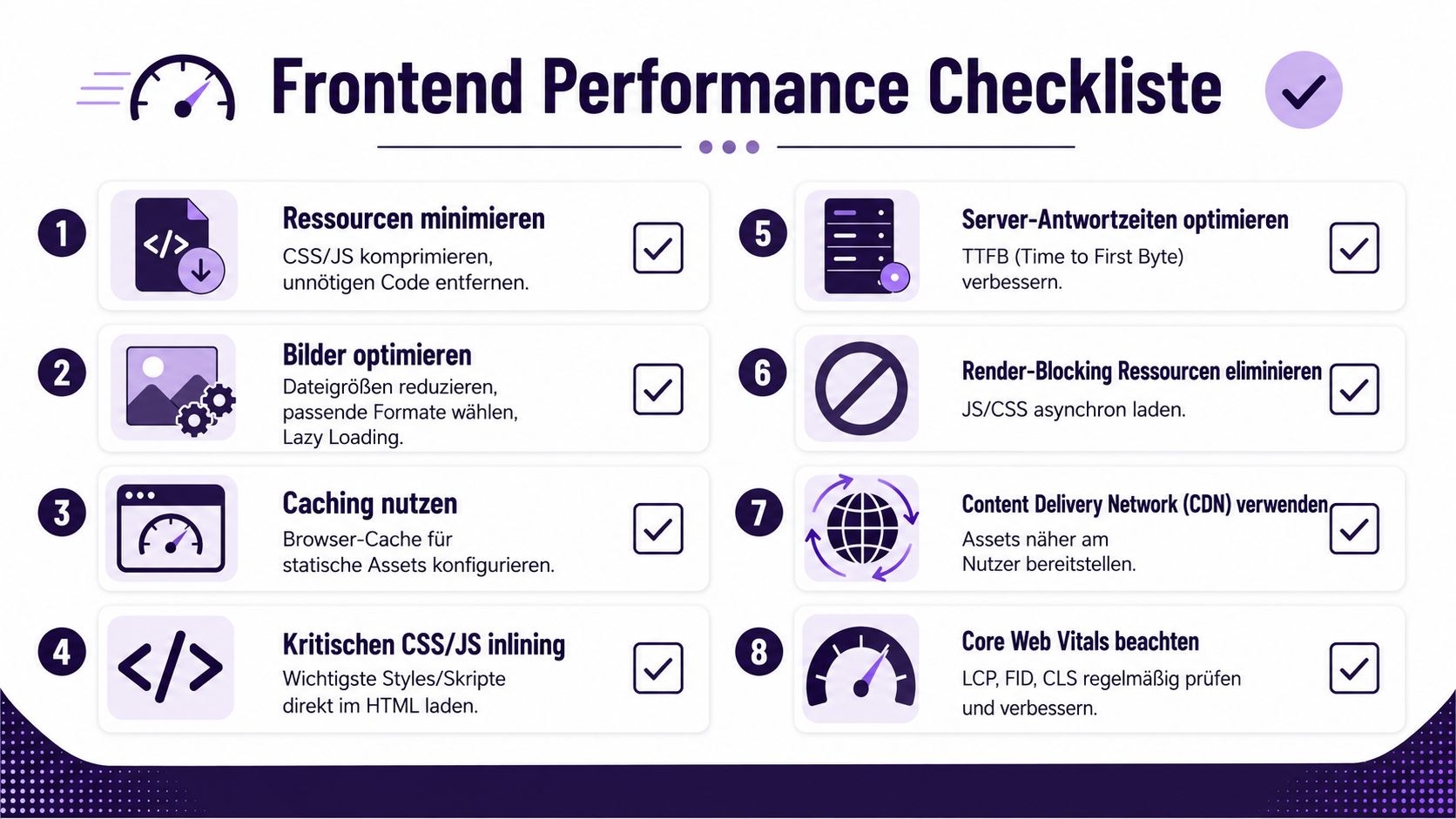
Beginnen Sie nicht mit Framework-Dogmen. Beginnen Sie mit den Bremsen, die Nutzer direkt spüren.
Core Web Vitals sind nützlich, aber sie ersetzen keine Produktkenntnis. Eine gute Metrik ist nur dann wertvoll, wenn Sie sie einem realen UX-Problem zuordnen können.
Wenn ein Team etwa nur den Erstaufruf misst, aber die eigentliche Nutzung in einem komplexen Dashboard stattfindet, bleibt der wichtigste Schmerzpunkt unsichtbar. Deshalb sollten Sie Frontend-Metriken immer mit konkreten Pfaden verbinden: Landing Page, Suche, Filterung, Formular, Checkout, Editor.
Ein pragmatischer Prüfpfad sieht oft so aus:
Die Wahl der Rendering-Strategie ist kein Glaubenskrieg. Sie ist eine Produktentscheidung.
Gerade bei mobilen oder schwächeren Geräten wirken sich unnötige Bibliotheken und schwergewichtige Komponenten besonders schnell aus. Teams, die an installierbaren Web-Erlebnissen arbeiten, finden im PandaNerds-Beitrag zu Progressive Web Apps einen sinnvollen Anknüpfungspunkt für die Verbindung von UX, Performance und App-Verhalten.
"Frontend-Performance ist dann gut, wenn Nutzer früh Rückmeldung erhalten und die Oberfläche stabil reagiert. Nicht dann, wenn nur ein Lighthouse-Wert hübsch aussieht."
Es gibt Situationen, in denen der Code akzeptabel ist und das System trotzdem langsam bleibt. Dann liegt der Engpass oft darunter oder dazwischen. Netzwerkpfade, Lastverteilung, externe Dienste, Container-Limits, Datenbanktopologie oder ein unglücklicher Schnitt in der Architektur können jede lokale Optimierung auffressen.
Ein oft übersehener Engpass ist die Netzwerkperformance, besonders bei verteilten Teams und Cloud-Anwendungen. Die entscheidende Frage lautet nicht immer „Wie optimiere ich Code?“, sondern „Wann ist der Engpass eigentlich Netzwerk, Observability oder Architektur?“ (Michael Wessel zu Performanceanalysen und Netzwerkengpässen).

Vertikale Skalierung ist einfach. Mehr CPU, mehr RAM, grösserer Datenbank-Knoten. Das kann kurzfristig sinnvoll sein, vor allem wenn Sie schnell Stabilität brauchen. Es löst aber keine chattige Architektur und keine ineffizienten Lastpfade.
Horizontale Skalierung verteilt Last besser, erhöht aber den Abstimmungsaufwand. Session-Handling, Cache-Konsistenz, Queue-Semantik und Netzwerkverkehr werden dann Teil des Problems.
Wer Infrastruktur auch unter Effizienzgesichtspunkten bewertet, findet im Rechenzentrum Effizienz Leitfaden zusätzliche Perspektiven auf Betrieb, Auslastung und technische Rahmenbedingungen.
Schlechte Lasttests testen nur die Startseite oder einen künstlichen API-Call in Schleife. Gute Lasttests modellieren echte Nutzung. Dazu gehören Mischlast, unterschiedliche Request-Arten, Authentifizierung, Datenabhängigkeiten und realistische Pausen zwischen Aktionen.
Achten Sie besonders auf diese Punkte:
Für Teams, die Cloud-Architektur in AWS bewerten, ist auch dieser PandaNerds-Beitrag zu Web Hosting in AWS relevant, weil Hosting-Entscheidungen direkten Einfluss auf Latenz, Skalierung und Betriebsmodell haben.
Die Liste möglicher Optimierungen ist praktisch endlos. Das Budget nicht. Deshalb ist die wichtigste Managementfrage nicht, was technisch machbar wäre, sondern welche Performance-Optimierung wirtschaftlich sinnvoll ist.
Laut KPMG wird Performance-Optimierung in Deutschland als unternehmensweite Steuerungsaufgabe verstanden, die Technologie, Skill-Aufbau und Kapitaldisziplin kombiniert. Sie ist damit mehr als eine technische Übung und eine Reaktion auf zunehmende Wettbewerbsintensität (KPMG zu Performance-Steigerung und Resilienz).
In der Praxis funktioniert eine einfache Impact-Effort-Logik gut. Nicht mathematisch perfekt, aber operativ klar.
Nicht jede Verzögerung ist geschäftskritisch. Wenn ein selten genutzter Export etwas länger läuft, ist das oft akzeptabel. Wenn aber Suchergebnisse spät erscheinen oder ein Formular träge reagiert, wirkt sich das direkt auf Nutzung und Conversion aus.
Die Kunst liegt darin, Performance an Produktwirkung zu koppeln:
Externe Expertise lohnt sich dann, wenn das interne Team in einer Schleife feststeckt. Typische Signale sind wiederholte Fehldiagnosen, zu viele parallele Hypothesen, fehlende Produktionsnähe in der Analyse oder eine Roadmap, die durch Performance-Themen blockiert wird.
Dann hilft meist keine weitere Meinungsrunde, sondern Senior-Erfahrung in Analyse, Priorisierung und Umsetzung. Das kann ein spezialisierter Consultant sein, ein externer Performance Engineer oder ein zusätzlich eingebundener Senior-Entwickler. PandaNerds ist in diesem Kontext eine Option für Unternehmen, die ihr Team temporär mit erfahrenen Entwicklern verstärken wollen, ohne langfristige Personalbindung aufzubauen.
Wichtig ist dabei weniger der Name des Partners als das Vorgehen: klare Messbasis, begrenzter Scope, belastbare Hypothesen und eine Übergabe, die das interne Team danach selbst weiterführen kann.
Wenn Performance-Probleme Ihre Roadmap bremsen oder Ihr Team gezielt Senior-Unterstützung für Analyse und Umsetzung braucht, kann PandaNerds eine passende Ergänzung sein. PandaNerds stellt erfahrene Entwickler bereit, die sich in bestehende Teams integrieren und technische Engpässe strukturiert bearbeiten.
































































































.svg)


