.jpeg)
02.07.2025
Asana vs. Trello: Welches Projektmanagement-Tool ist besser?
Asana vs. Trello: Welches Projektmanagement-Tool ist besser? Wir vergleichen beide Tools im Projektmanagement. Welches Tool passt besser zu Ihren Zielen?
get started
.svg)

Ihr Entwicklerteam arbeitet am nächsten Release. Gleichzeitig landen im Slack-Channel Fragen zu Login-Problemen, unklaren Fehlermeldungen, Rechte-Themen und vermeintlichen Bugs, die am Ende nur ein Bedienfehler sind. Jedes einzelne Thema wirkt klein. In Summe zerlegt es den Arbeitstag.
Genau an diesem Punkt wird Support Level 1 entweder zur Kostenstelle oder zum Hebel. Schlecht aufgestellt produziert L1 nur Ticket-Weiterleitungen und Frust. Gut aufgestellt schützt es die Fokuszeit von Engineering, verkürzt die Zeit bis zur Lösung für Kunden und liefert Signale, die Produktteams sonst zu spät sehen.
Für CTOs und Tech-Leads ist das keine operative Nebensache. Es ist eine Architekturfrage. Wer L1 sauber definiert, spart nicht nur Unterbrechungen, sondern baut einen kontrollierten Filter zwischen Kundenrealität und Entwicklerkapazität.
Die teuerste Ressource in vielen Software-Teams ist nicht Infrastruktur. Es ist ungestörte Zeit von erfahrenen Entwicklern. Sobald Senior Engineers wiederholt einfache Supportfälle übernehmen, zahlt die Organisation mehrfach. Features verzögern sich, Kontextwechsel häufen sich, und Kunden bekommen oft trotzdem keine konsistente Antwort.
Ein starker Support Level 1 löst dieses Problem nicht dadurch, dass er Tickets nur “vom Tisch” bekommt. Er schafft Ordnung an der Eintrittsstelle. Das Team trennt echte Produktfehler von Bedienproblemen, erfasst reproduzierbare Informationen und beantwortet Standardanfragen schnell und sauber. Engineering bekommt dadurch weniger Lärm und bessere Signale.
"Praxisregel: Jeder Fall, den L1 selbst lösen kann, spart nicht nur Zeit. Er spart vor allem den Kontextwechsel in L2, L3 und Produktentwicklung."
Viele Teams betrachten First-Level-Support als reine Servicerolle. Das ist zu kurz gedacht. L1 ist ein strategischer Puffer zwischen Nutzern und Entwicklungsorganisation.
Wenn dieser Puffer funktioniert, entstehen drei direkte Effekte:
Gut funktioniert ein L1-Team, wenn Zuständigkeiten, Entscheidungsspielräume und Eskalationswege klar sind. Dann kann es eigenständig handeln. Schlecht funktioniert es, wenn Agents für jede Kleinigkeit Rückversicherung bei Product oder Engineering brauchen.
Ein häufiger Fehler ist die falsche Besetzung. Wer L1 nur nach “freundlich am Telefon” besetzt, bekommt nette Kommunikation, aber schlechte Triage. Wer nur auf technische Härte setzt, bekommt oft korrekte Antworten ohne Servicegefühl. Für ein starkes Setup braucht L1 beides. Struktur und Kundenorientierung.
Support Level 1 ist die erste operative Anlaufstelle für eingehende Kundenanfragen. Dort beginnt die Bearbeitung fast aller Fälle. L1 nimmt Kontakt auf, versteht das Problem, versucht eine Erstlösung auf Basis bekannter Muster und entscheidet, ob ein Fall gelöst, dokumentiert oder qualifiziert eskaliert werden muss.
Das klingt einfach. In der Praxis ist genau diese Schicht oft der Unterschied zwischen einem lernenden Support-System und einem eskalationsgetriebenen Chaos. Eine gute Einführung in den Aufbau eines solchen Einstiegs finden Sie auch im Beitrag zum First-Level-Support im IT-Umfeld.
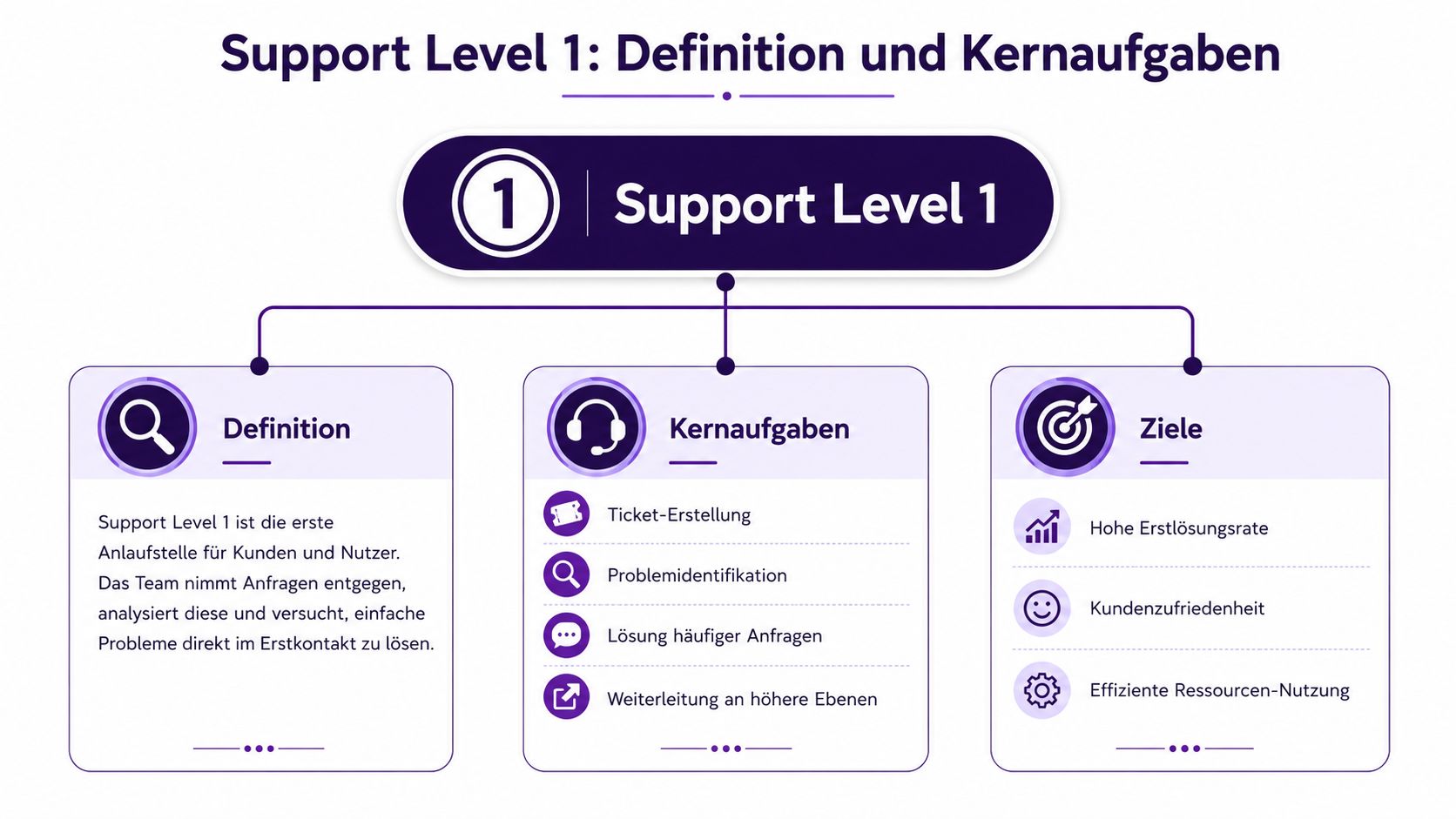
L1 ist keine verkleinerte Entwicklerrolle. Es ist eine Triage-, Lösungs- und Dokumentationsfunktion mit klarer Verantwortung am Frontend des Supports.
Typische Kernaufgaben sind:
Die Grenzziehung ist genauso wichtig wie die Aufgabenliste. L1 sollte keine halbgaren technischen Vermutungen an Kunden senden und keine Fehlerbilder “wegmoderieren”, die tatsächlich Analyse brauchen. Ebenso problematisch ist es, wenn L1 direkt in produktive Systeme eingreift, ohne klaren Rahmen, Rechtekonzept oder dokumentierte Standardprozedur.
Eine kurze Abgrenzung hilft oft in Stellenprofilen und Betriebsmodellen:
"Ein schwaches L1-Team eskaliert Fragen. Ein starkes L1-Team liefert bereits eingegrenzte Probleme."
Gutes L1 erkennt man selten an besonders spektakulären Einzelfällen. Man erkennt es daran, dass Tickets konsistent aussehen, Kunden nicht mehrfach dieselben Informationen liefern müssen und Engineering-Tickets mit verwertbarem Kontext ankommen.
Das ist operative Exzellenz. Und genau sie entlastet teure Teams im Hintergrund.
Viele Support-Organisationen scheitern nicht an fehlenden Leuten, sondern an unscharfen Übergaben. Wenn niemand sauber definiert hat, was Support Level 1, Level 2 und Level 3 jeweils leisten, werden Tickets entweder zu früh oder zu spät eskaliert. Beides ist teuer.
Die einfachste Abgrenzung lautet so: L1 bearbeitet bekannte und standardisierbare Fälle. L2 untersucht technische Probleme, die tieferes Produktwissen erfordern, aber noch ohne Eingriff in Code oder Architektur lösbar sind. L3 übernimmt Themen, bei denen Produktlogik, Infrastruktur oder Softwareänderungen betroffen sind.
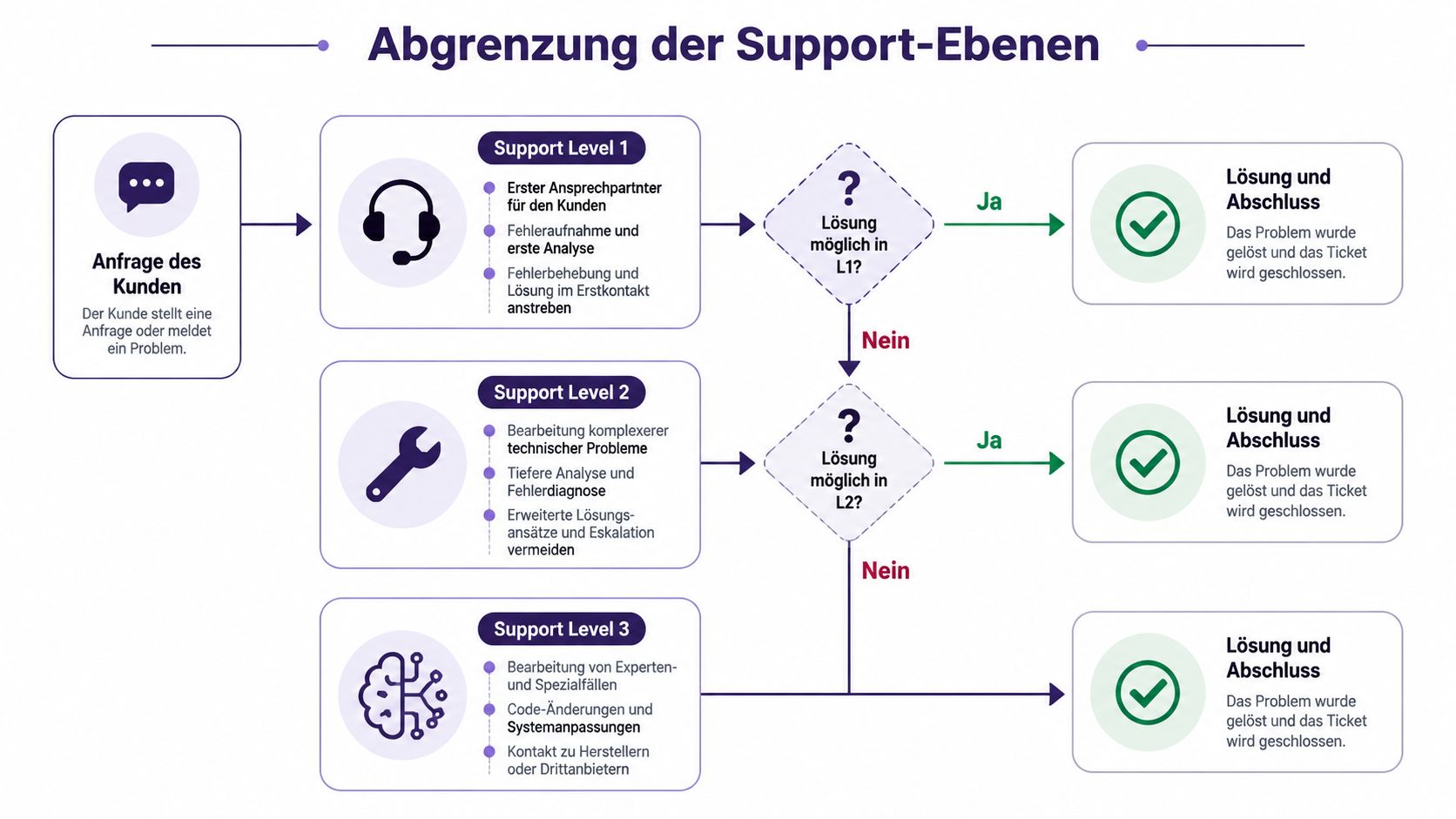
Für Teams, die ihre zweite Eskalationsstufe schärfer definieren wollen, ist eine klare Beschreibung von Level-2-Support-Aufgaben und Zuständigkeiten hilfreich.
Die Abgrenzung wird klarer, wenn man sie an typischen Fällen aufhängt:
Die Eskalationsentscheidung darf nicht vom Bauchgefühl abhängen. Gute Teams definieren Trigger, die L1 sicher anwenden kann.
Sinnvolle Eskalationskriterien sind:
"Gute Eskalation heisst nicht, ein Ticket weiterzuleiten. Gute Eskalation heisst, den nächsten Bearbeitungsschritt vorzubereiten."
Die Qualität von L2 und L3 hängt stark davon ab, wie L1 übergibt. Ein eskaliertes Ticket ohne Kontext ist nur ein verschobener Aufwand.
Mindestens enthalten sein sollten:
Was nicht funktioniert, ist die klassische Eskalation mit dem Satz: “Kunde meldet Fehler, bitte prüfen.” Damit wird L2 zum zweiten First-Level-Support. Genau das sollte die Struktur verhindern.
Ein L1-Team wird nicht dadurch gut, dass es beschäftigt aussieht. Es wird gut, wenn sein Workflow stabil ist und seine Kennzahlen die richtigen Fragen beantworten. Für CTOs ist dabei wichtig, Metriken nicht als Reporting-Dekoration zu behandeln, sondern als Diagnosewerkzeug.
Die Kennzahlen im Support Level 1 sagen nicht nur etwas über Support aus. Sie zeigen oft auch, ob Onboarding, UX, Dokumentation und Release-Kommunikation funktionieren.
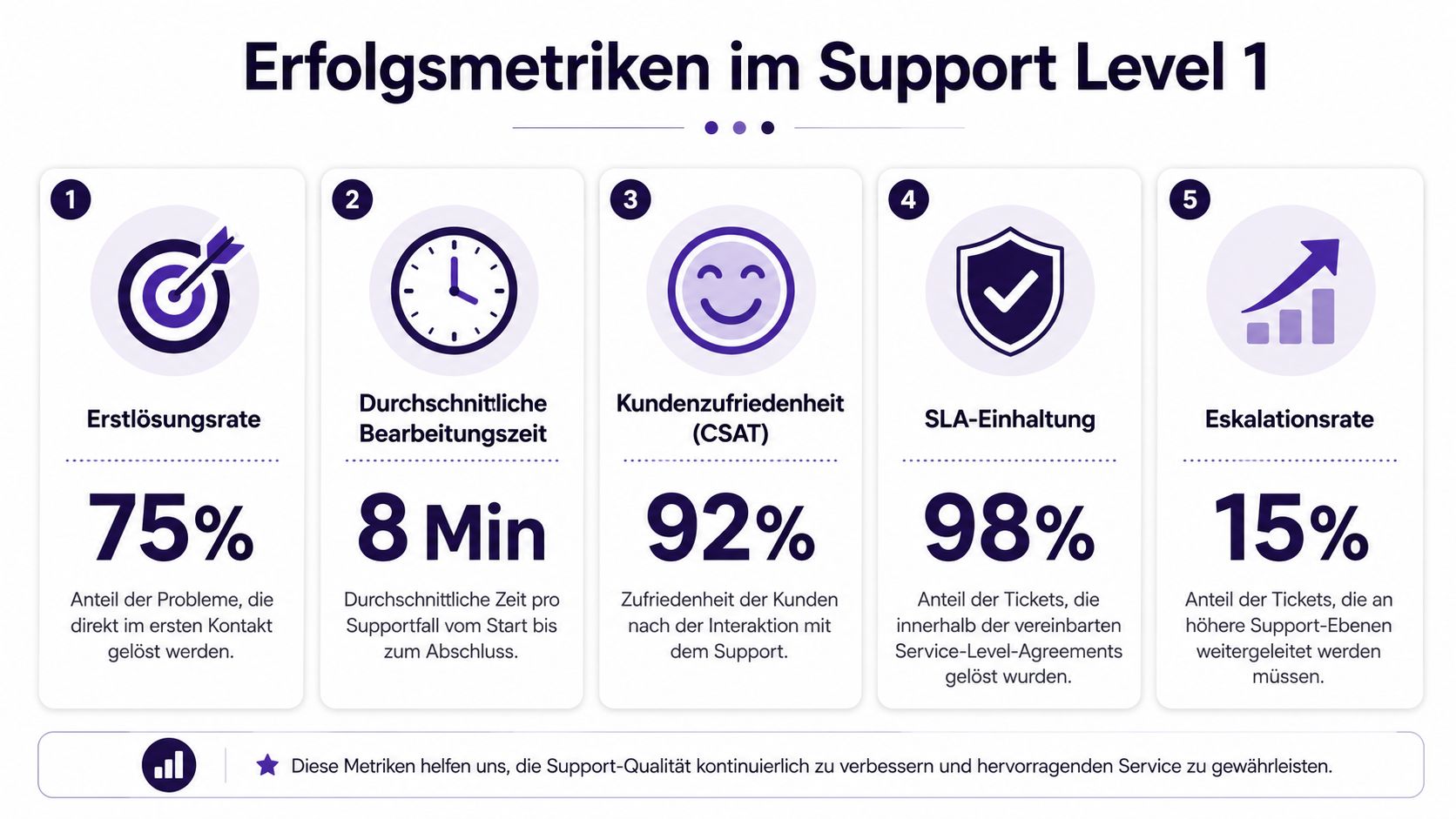
Wichtig ist dabei ein methodischer Hinweis: Die eingeblendeten Werte in der Grafik sind Teil der Visualisierung. Für die operative Steuerung sollten Sie eigene Zielwerte aus Ihrem Produkt, Ihrer Kundenstruktur und Ihrem Serviceversprechen ableiten.
Nicht jede Kennzahl ist gleich wertvoll. Einige sind führend, andere eher nachgelagert.
Starke Teams standardisieren nicht jede Formulierung, aber sie standardisieren den Ablauf. Ein solider Ticketprozess umfasst meist diese Stationen:
Ein häufiger Fehler ist es, zu viel Energie in Dashboards und zu wenig in Ticket-Hygiene zu stecken. Wenn Kategorien unklar, Felder leer und Abschlussgründe unpräzise sind, produziert das Reporting nur scheinbare Erkenntnisse.
Der Return von L1 liegt selten nur im Support selbst. Er liegt in geschützter Entwicklerzeit, geringerer Eskalationslast und saubereren Produktsignalen. Deshalb sollte ein CTO nicht nur fragen, wie viele Tickets L1 bearbeitet, sondern auch:
"Entscheidungshilfe: Wenn Ihre Metriken nur Geschwindigkeit messen, optimieren Sie Hektik. Wenn sie Ursachen sichtbar machen, optimieren Sie das System."
Ein starkes L1-Team entsteht selten zufällig. Die grössten Fehlbesetzungen passieren, wenn Unternehmen die Rolle entweder rein administrativ oder rein technisch verstehen. Beides greift zu kurz. Wer im Support Level 1 arbeitet, braucht Kommunikationsstärke, Mustererkennung, Disziplin in der Dokumentation und genug technisches Grundverständnis, um relevante von irrelevanten Informationen zu unterscheiden.
Die Rolle ist anspruchsvoller, als viele Jobtitel vermuten lassen. Ein guter L1-Agent beruhigt Kunden, denkt strukturiert, arbeitet sauber mit Tools und erkennt, wann ein Fall eskaliert werden muss. Das ist operative Urteilskraft.
Die besten L1-Mitarbeiter kombinieren drei Kompetenzfelder:
Im Hiring lohnt es sich, weniger auf Selbstbeschreibungen und mehr auf Arbeitssituationen zu schauen. Statt “Sind Sie kundenorientiert?” bringt eine Fallfrage deutlich mehr. Zum Beispiel: Ein Kunde meldet “Die Plattform funktioniert nicht”. Was fragen Sie zuerst nach, wie priorisieren Sie und wann eskalieren Sie?
Es gibt nicht das eine richtige Staffing-Modell. Die Wahl hängt von Produktkomplexität, Verfügbarkeit von internem Wissen, Sprachbedarf und Steuerungsreife ab.
In vielen Scale-ups funktioniert ein gemischtes Modell am besten. Kernwissen bleibt intern, Spitzenlast oder definierte Schichten werden flexibel ergänzt. Entscheidend ist nicht die Vertragsform, sondern ob Prozesse, Qualität und Kommunikation gemeinsam geführt werden.
Viele Teams onboarden L1 einmal und wundern sich später über schwankende Qualität. Das Problem ist selten fehlende Motivation. Es fehlt ein Lernsystem.
Ein belastbares Setup enthält:
"Wer L1 nur auf Antworten trainiert, bekommt Script-Nutzung. Wer L1 auf Problemverständnis trainiert, bekommt bessere Entscheidungen."
Ohne passende Werkzeuge bleibt selbst ein gutes Team langsam. Mit dem richtigen Stack wird Support Level 1 konsistent, nachvollziehbar und skalierbar. Der Kern ist fast immer ein zentrales Helpdesk-System. Ob Teams mit Zendesk, Jira Service Management oder Freshdesk arbeiten, ist weniger entscheidend als die Frage, ob Ticketstruktur, Automationen und Reporting zum Produkt passen.

Eine gute Übersicht über Anforderungen an ein zentrales Ticketsystem bietet auch der Beitrag zu Helpdesk-Lösungen im IT-Support.
Ein funktionierender Stack besteht meist aus drei Bausteinen.
Erstens das Helpdesk-System. Es bündelt E-Mail, Webformulare und Chat, steuert Zuweisungen und macht Status transparent. Entscheidend sind saubere Felder, gute Makros, SLA-Logik und belastbare Integrationen zu CRM, Produkt- oder Incident-Tools.
Zweitens die Wissensdatenbank. Sie ist kein Ablageort für veraltete Anleitungen, sondern das operative Gedächtnis des Teams. Gute Knowledge Bases sind kurz, versioniert und so geschrieben, dass L1 sie unter Zeitdruck nutzen kann. Dasselbe Wissen sollte, wo sinnvoll, auch Kunden im Self-Service helfen.
Drittens Automatisierung. Routing-Regeln, Textbausteine, Vorqualifizierung und einfache Chatflows sparen Zeit. Aber Automatisierung ist nur dann hilfreich, wenn sie Reibung entfernt. Schlechte Bots verlängern Wege, weil Kunden erst durch unpassende Menüs laufen müssen.
Diese Aufgaben lassen sich meist gut automatisieren:
Vorsicht ist bei Themen geboten, die Kontext, Empathie oder Risikoabwägung brauchen. Sicherheitsfragen, Abrechnungsstreitigkeiten oder unklare Produktfehler sollten nicht in starre Bot-Dialoge gepresst werden.
Wer Chat als Eingangskanal nutzt, sollte ausserdem auf eine saubere Supervisor-Sicht achten. Eine gut strukturierte admin chat interface hilft dabei, laufende Konversationen zu steuern, Übergaben sauber zu organisieren und Gesprächskontext nicht zu verlieren.
Für einen kompakten Überblick zu gängigen Support-Werkzeugen ist dieses Video nützlich:
Unternehmen kaufen oft zu früh komplexe Plattformen und zu spät saubere Prozesse. Ein übermächtiges Tool ersetzt keine klare Ticketlogik. Wenn Felder niemand pflegt, Makros unkontrolliert wachsen und Wissensartikel veralten, skaliert nur das Chaos.
Die wirksamste Verbesserung beginnt selten mit einem grossen Reorganisationsprojekt. Meist beginnt sie mit einem nüchternen Audit. Wenn Sie Ihren Support Level 1 bewerten wollen, prüfen Sie nicht nur Reaktionszeiten, sondern das gesamte System aus Rollen, Entscheidungen, Werkzeugen und Rückkopplungen.

Nutzen Sie diese Liste als operative Bestandsaufnahme:
Einige Symptome deuten fast immer auf strukturelle Schwächen hin:
"Ein starkes L1-Team schützt nicht nur den Support. Es schützt die Entwicklungsorganisation vor vermeidbarer Reibung."
Wenn Sie bei mehreren Punkten zögern, liegt das Problem meist nicht an einzelnen Mitarbeitern. Es liegt an fehlender Struktur. Genau dort lohnt sich die Investition zuerst.
Wenn Sie Ihr Support-Setup entlasten und gleichzeitig Ihre Engineering-Kapazität sauber auf Produktarbeit fokussieren wollen, lohnt sich ein Blick auf PandaNerds. Das Team unterstützt Unternehmen dabei, erfahrene Entwickler flexibel in bestehende Strukturen einzubetten, damit technische Eskalationen dort landen, wo sie hingehören, ohne den Alltag Ihres Kernteams zu zerlegen.
































































































.svg)


